文章目录[隐藏]
声明:
我不建议大家盲目去抓人家的站,去拿人家的东西。读书人的事情不算偷,但别因为贪婪就去干竭泽而渔的事情,最终原意公开的人越来越少,大家更难拿到研究资料。
真正有需求,请去购买正版!
我写上篇二字的原因是这篇仅仅针对于一个变量,而不是多个。(或者叫通配符。后续你就会发现了。)
需求
- PC;
- IDM;
- 浏览器用火狐、谷歌、edge都行,要F12看得到东西的;
- 一定的动手能力和耐心。
(如果认为这个教程步骤太多,建议直接放弃。如果有更好的方法,请直接联系我。); - EmEditor等文本编辑器;
- 四级英语;
- 魔法上网(部分需要)。
思路分析
你会发现很多图书馆给你在线看到话就是图片,(有几个东洋比较阴间的我就不点名了,玩到最后都清楚干了什么事情。)这样我们把图片下载下来不就可以了?
举例说明
例1(不加载高清图但是能看得到原数据,变量只有一个。)
我拿哈佛大学图书馆举个例子吧。这家其实是比较良心的,稍后就知道了。
随便搜一本可以在线看的(其实这本我早就下了。)。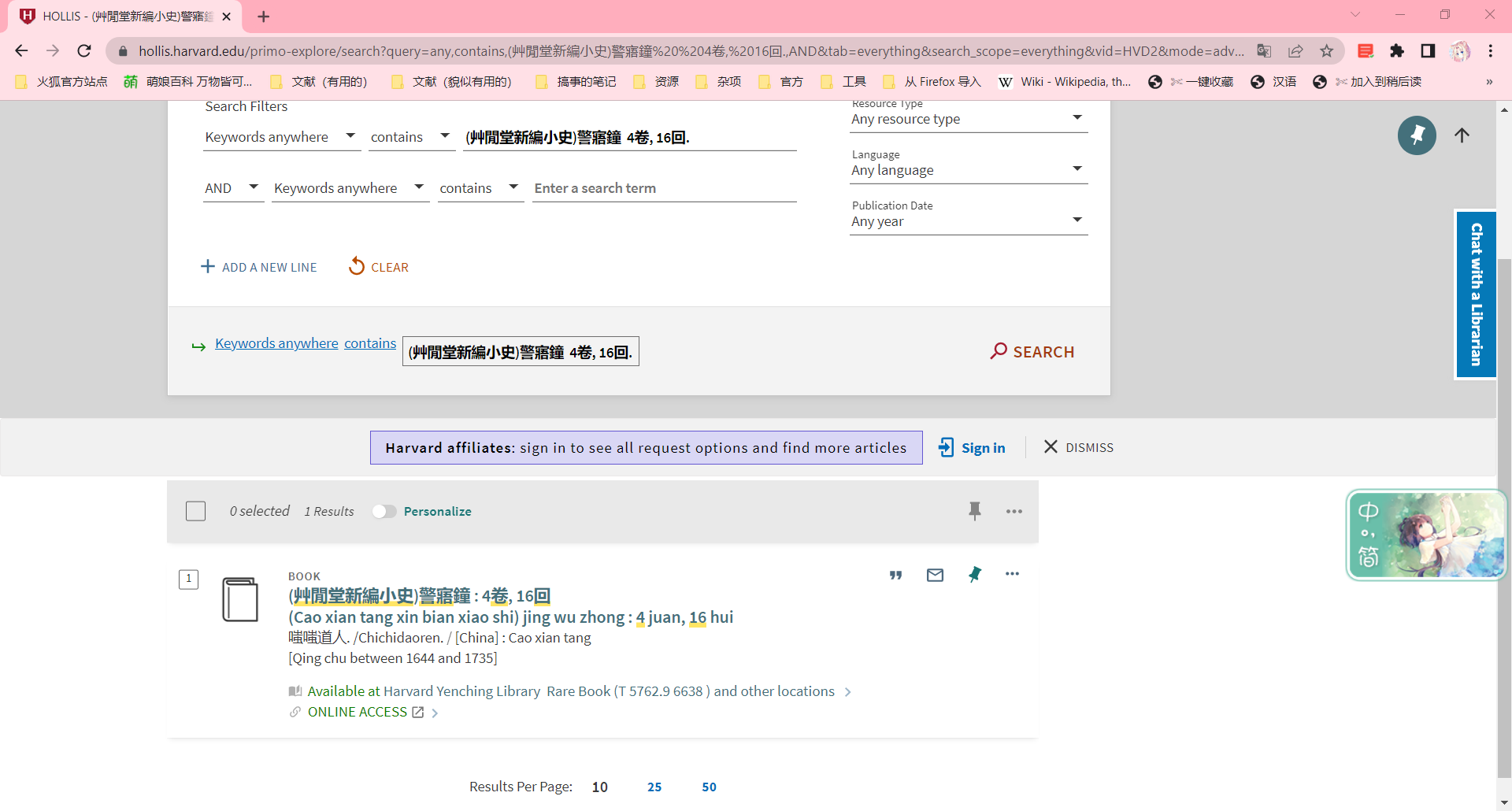
点进去(别和我说你找不到入口,我四级飘过都行。),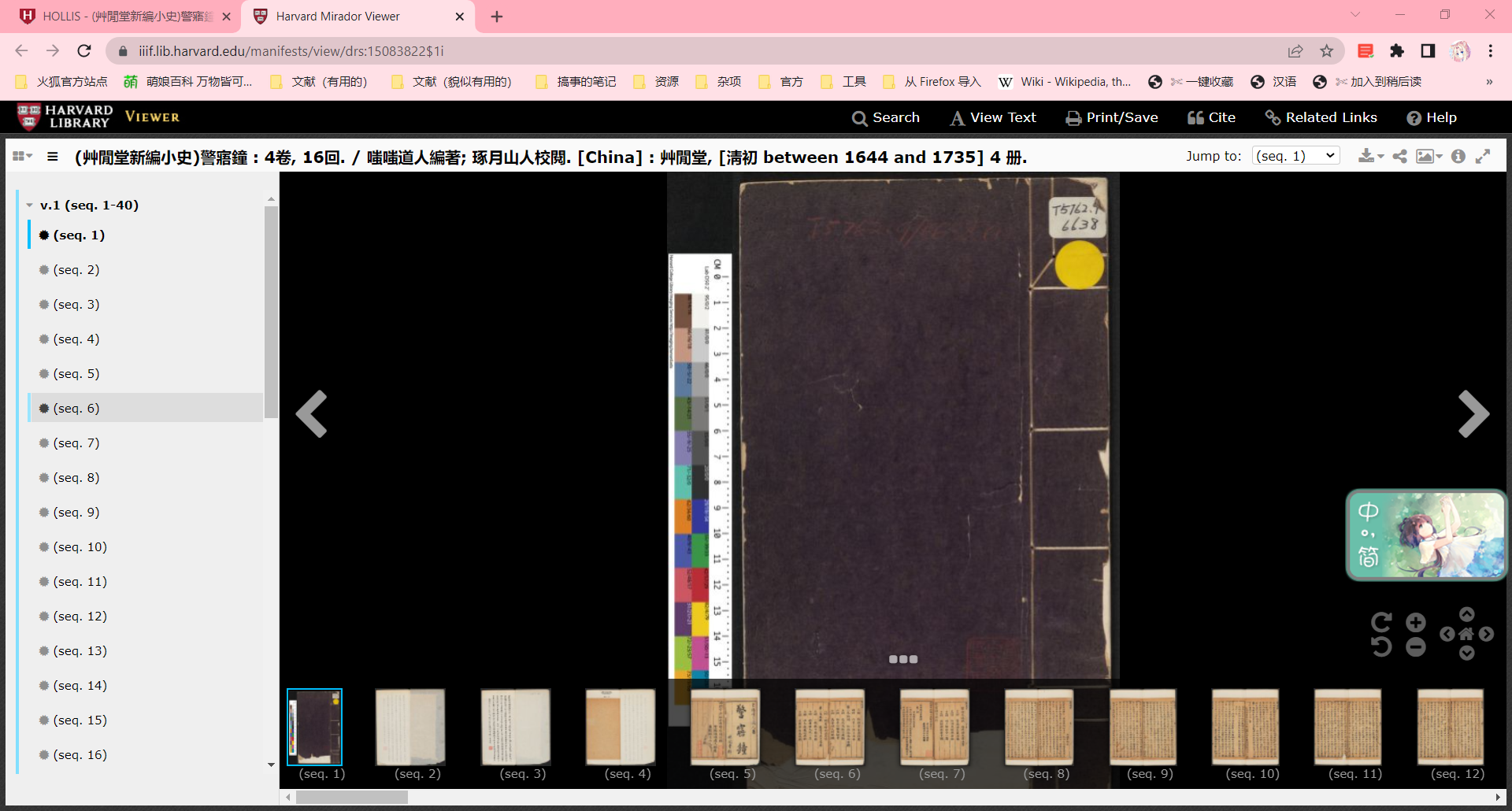
然后这样点。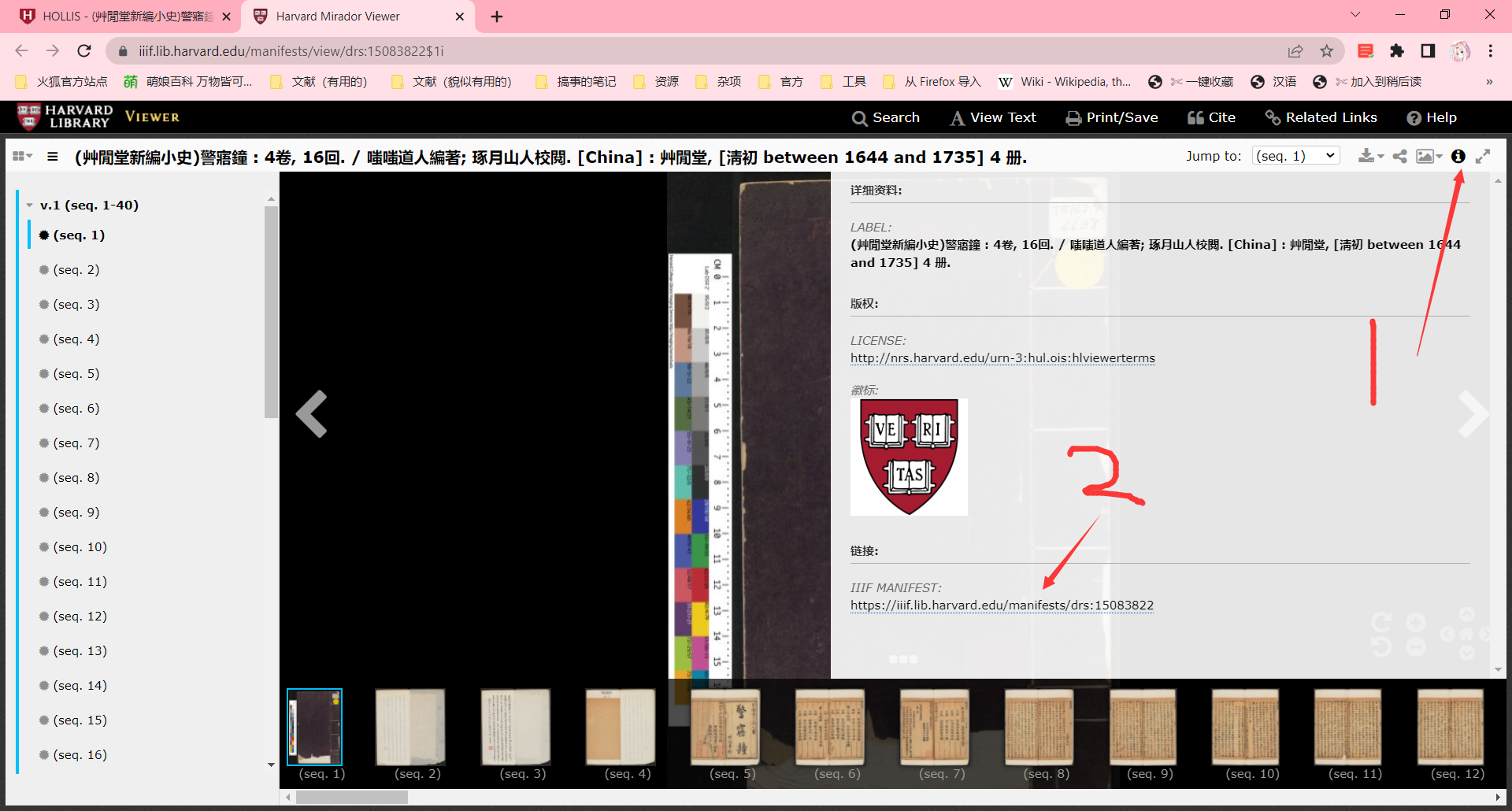
重点来了,我们要在这里面找东西。我换火狐了,可以美化一下输出,不然看的眼花。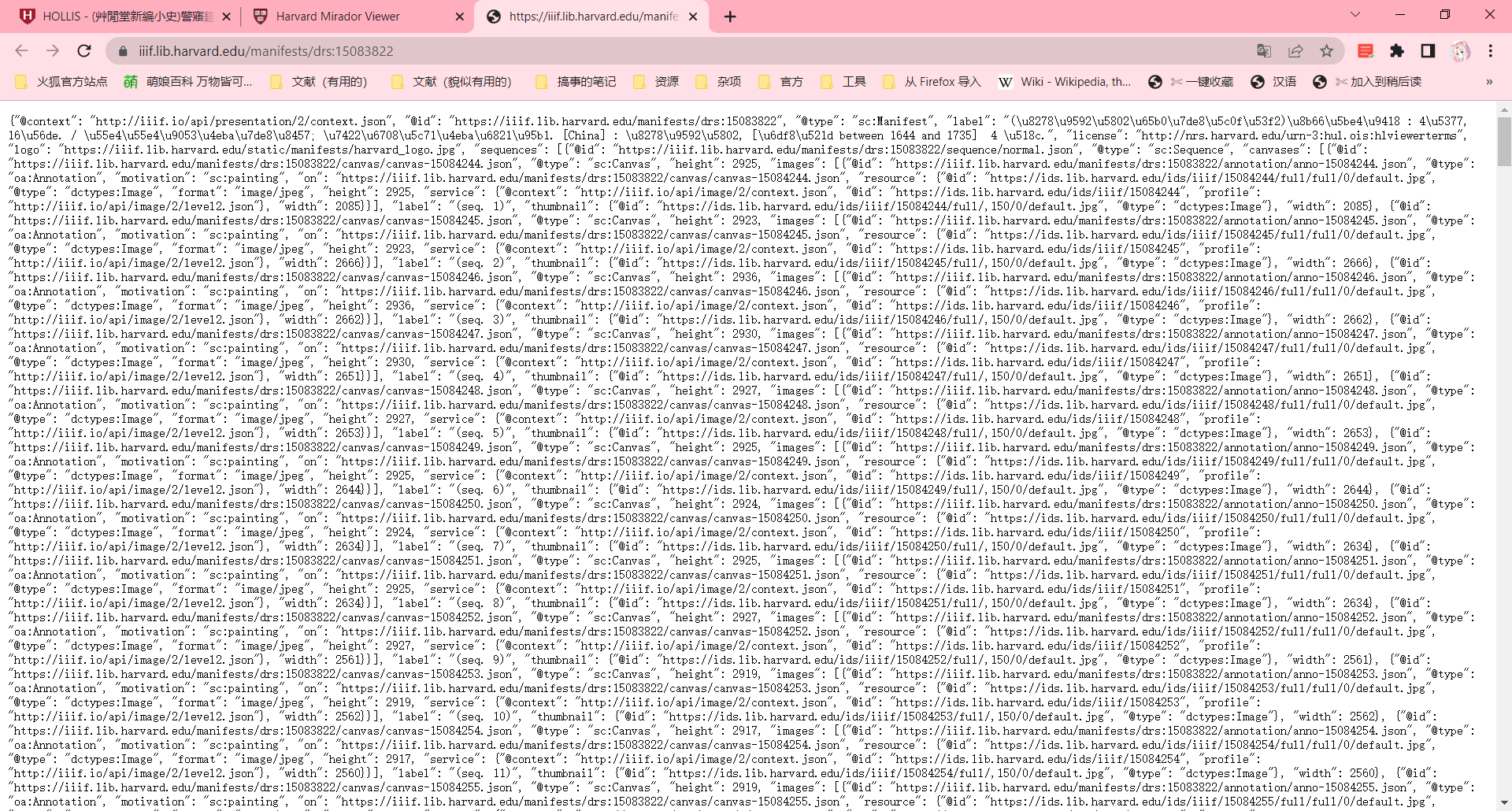
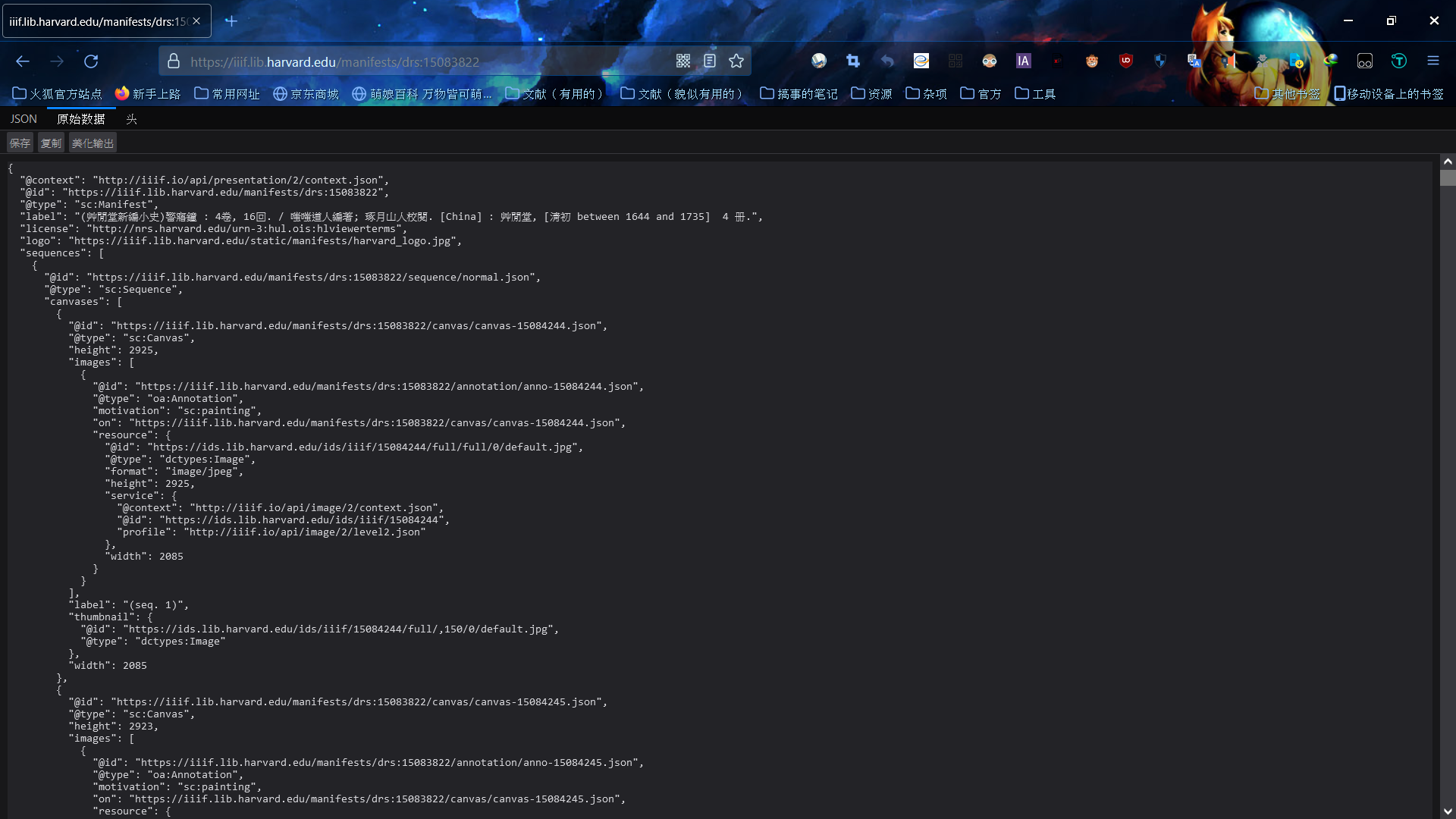
我们往下翻,找到这种字段。(既然是图片,肯定是找有JPG、PNG TIFF的)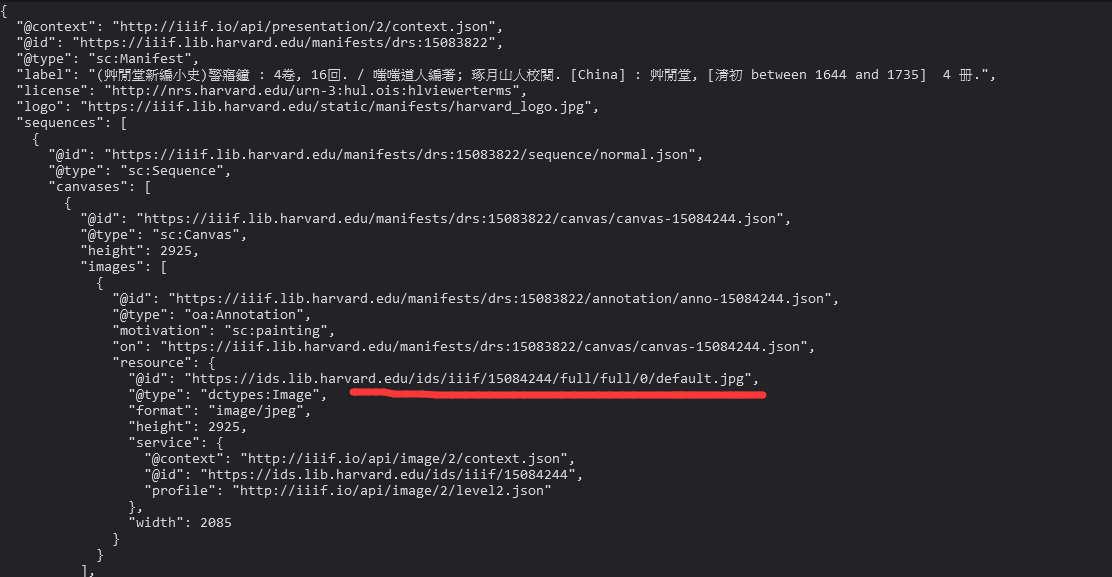
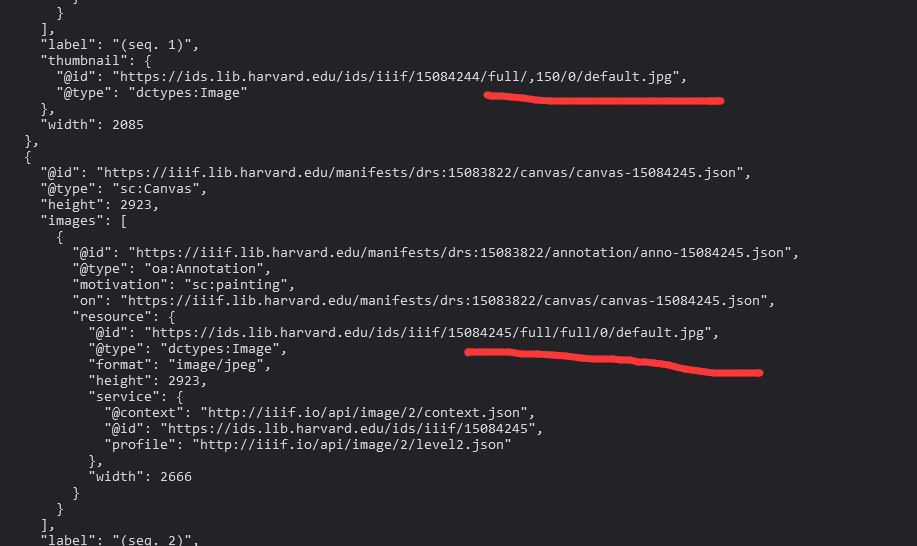
然后我们研究一下上下的链接差异如何。
"@id": "https://iiif.lib.harvard.edu/manifests/drs:15083822/sequence/normal.json",
"@type": "sc:Sequence",
"canvases": [
{
"@id": "https://iiif.lib.harvard.edu/manifests/drs:15083822/canvas/canvas-15084244.json",
"@type": "sc:Canvas",
"height": 2925,
"images": [
{
"@id": "https://iiif.lib.harvard.edu/manifests/drs:15083822/annotation/anno-15084244.json",
"@type": "oa:Annotation",
"motivation": "sc:painting",
"on": "https://iiif.lib.harvard.edu/manifests/drs:15083822/canvas/canvas-15084244.json",
"resource": {
"@id": "https://ids.lib.harvard.edu/ids/iiif/15084244/full/full/0/default.jpg",
"@type": "dctypes:Image",
"format": "image/jpeg",
"height": 2925,
"service": {
"@context": "http://iiif.io/api/image/2/context.json",
"@id": "https://ids.lib.harvard.edu/ids/iiif/15084244",
"profile": "http://iiif.io/api/image/2/level2.json"
},
"width": 2085
}
}
],
"label": "(seq. 1)",
"thumbnail": {
"@id": "https://ids.lib.harvard.edu/ids/iiif/15084244/full/,150/0/default.jpg",
"@type": "dctypes:Image"
},
"width": 2085
},
{
"@id": "https://iiif.lib.harvard.edu/manifests/drs:15083822/canvas/canvas-15084245.json",
"@type": "sc:Canvas",
"height": 2923,
"images": [
{
"@id": "https://iiif.lib.harvard.edu/manifests/drs:15083822/annotation/anno-15084245.json",
"@type": "oa:Annotation",
"motivation": "sc:painting",
"on": "https://iiif.lib.harvard.edu/manifests/drs:15083822/canvas/canvas-15084245.json",
"resource": {
"@id": "https://ids.lib.harvard.edu/ids/iiif/15084245/full/full/0/default.jpg",
"@type": "dctypes:Image",
"format": "image/jpeg",
"height": 2923,
"service": {
"@context": "http://iiif.io/api/image/2/context.json",
"@id": "https://ids.lib.harvard.edu/ids/iiif/15084245",
"profile": "http://iiif.io/api/image/2/level2.json"
},
"width": 2666
}
}
],
是不是相差了一位?注意这边我们要的是FULL,意思应该明白吧。总不可能研究了半天发现下来一堆小图。我这边要特别说明一点,不要担心大小问题。要么就别下,要么就别担心这个。
打开IDM,左上角点开,
有个添加批量任务,点进去。
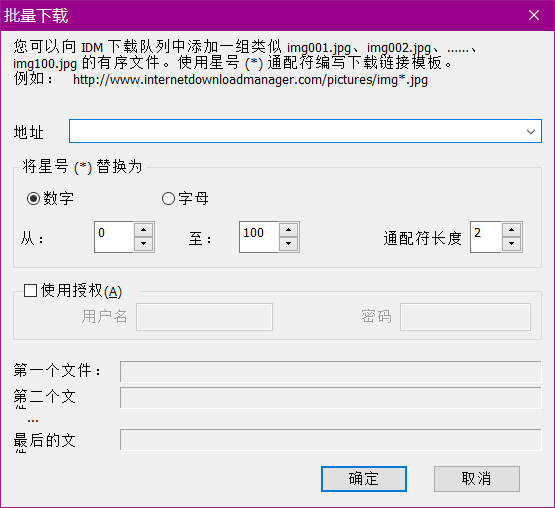
把我们刚刚找到的链接复制进去,再改一下,因为我们要让IDM实现递增过程。
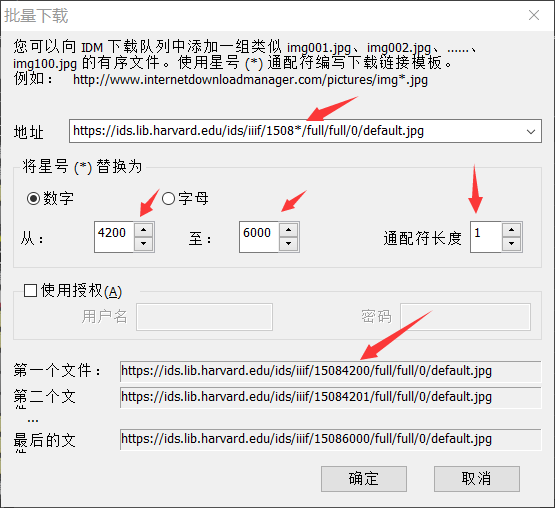
我依次说明,就不P图了。那个*的意思是替换的数字,或者说将原先的4245替换成*。

通配符长度就是依次递增的长度,比如说我每次页码增加1,就输入1即可。
它说不能超过1K个文件,我们改小一点,同时如果有超过1K页的书籍,我们分开爬取。
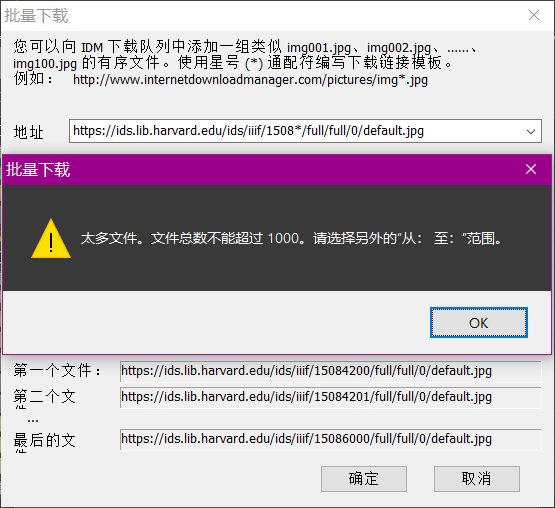
点击确定。
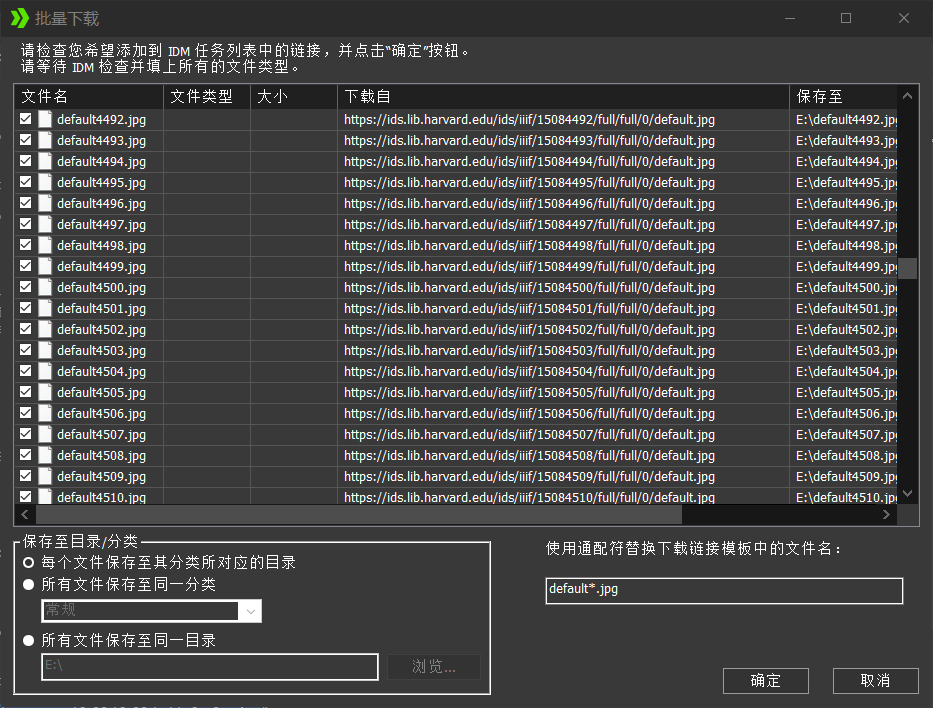
剩下的都是中文,自己选择吧,也没有什么难懂的。后续合成为PDF可以用Adobe自家的Acrobat。这个就自己挑一个版本吧。
例2(加载高清图但是看不到原数据,变量也只有一个。)
我以另一个图书馆举例,京都大学人文科学研究所。
点开刚刚的链接,我们看到了这个。
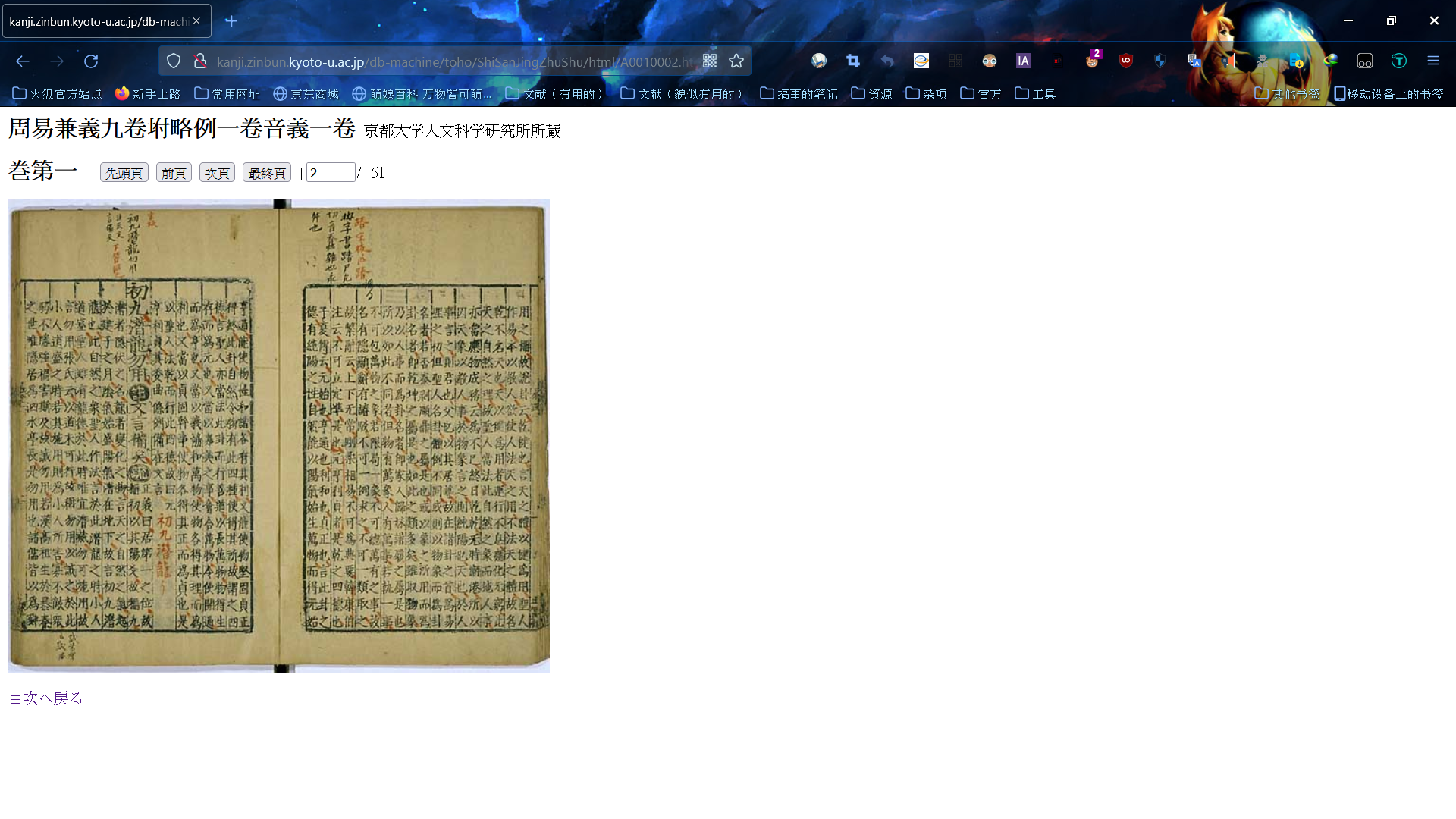
然后是不是感觉什么都没有,就一张图。这个时候请按下F12,并依次点击。
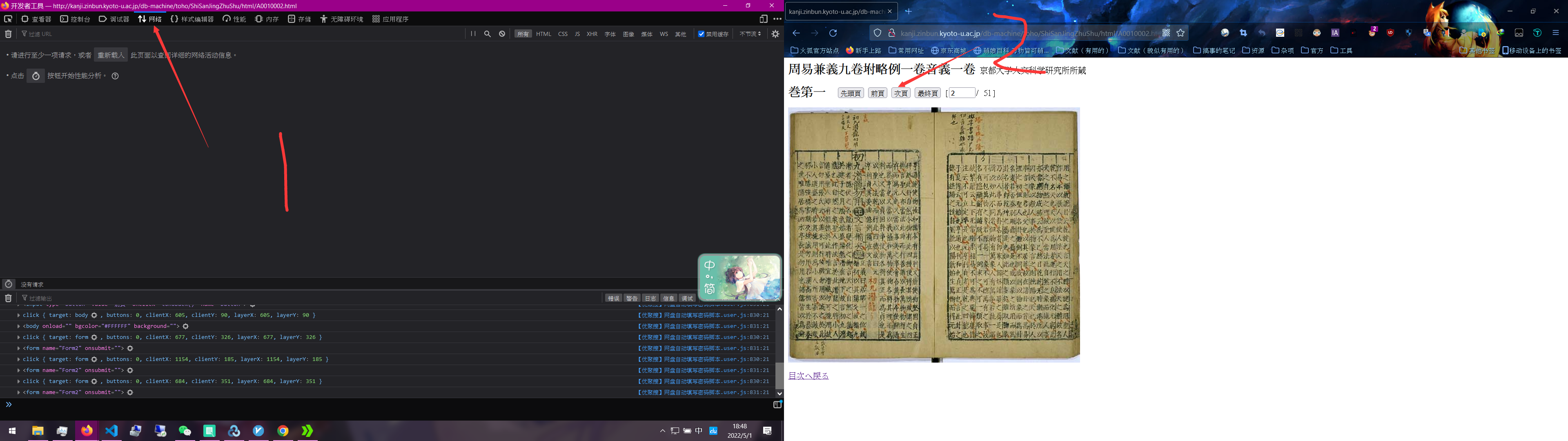
然后我们多点几下次页(也就是翻页的意思。顺便说一下,我这边不是拼图
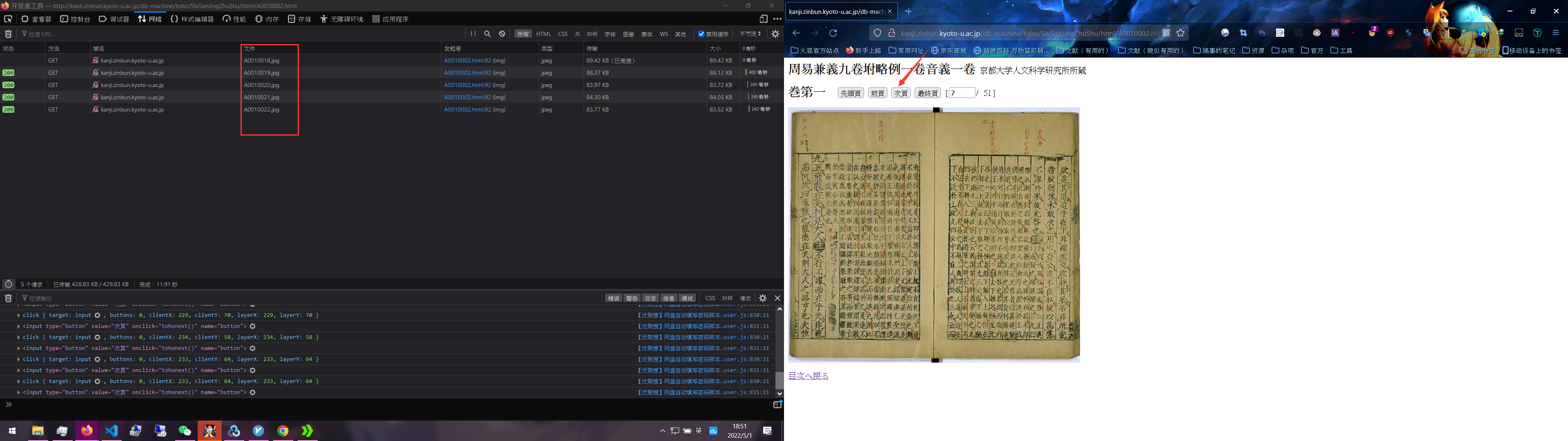
这样一来,我们要的图片链接就找到了,剩下和例1同理。
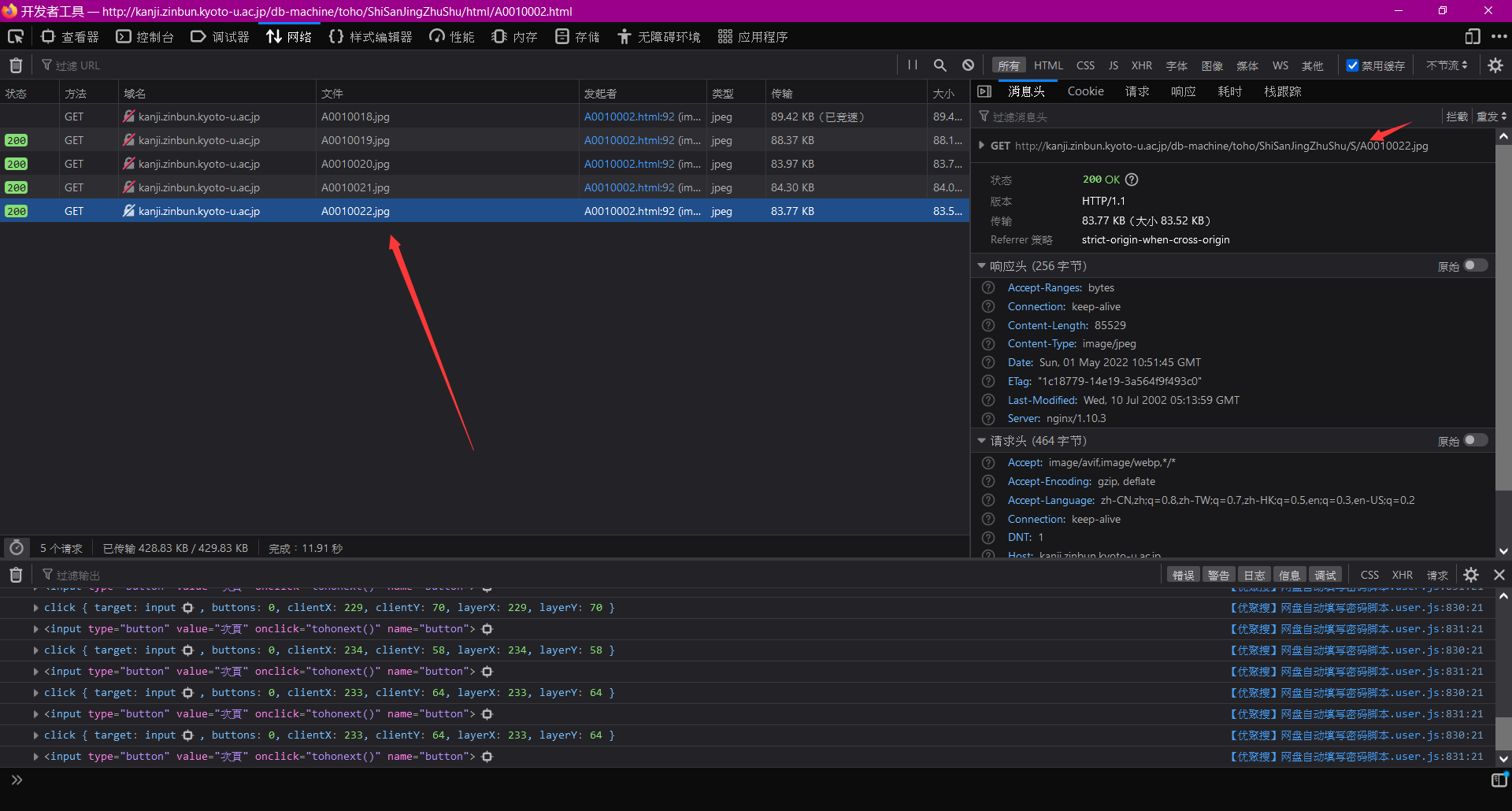
例3(不加载高清图,看不到原数据,有单页下载,变量只有一个)
我以HathiTrust图书馆为例说明。
打开即可搜索。
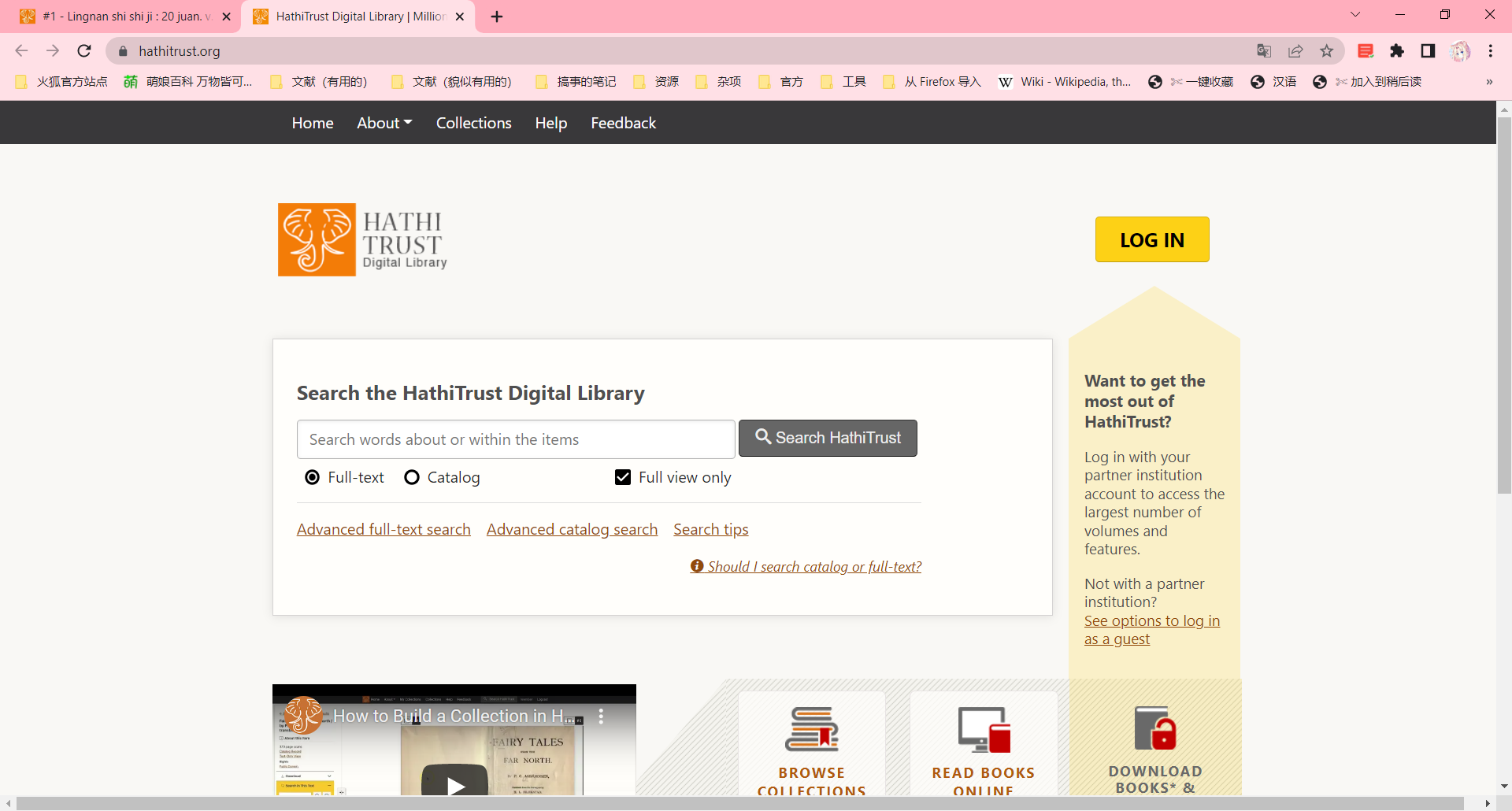
然后我们的搜索结果
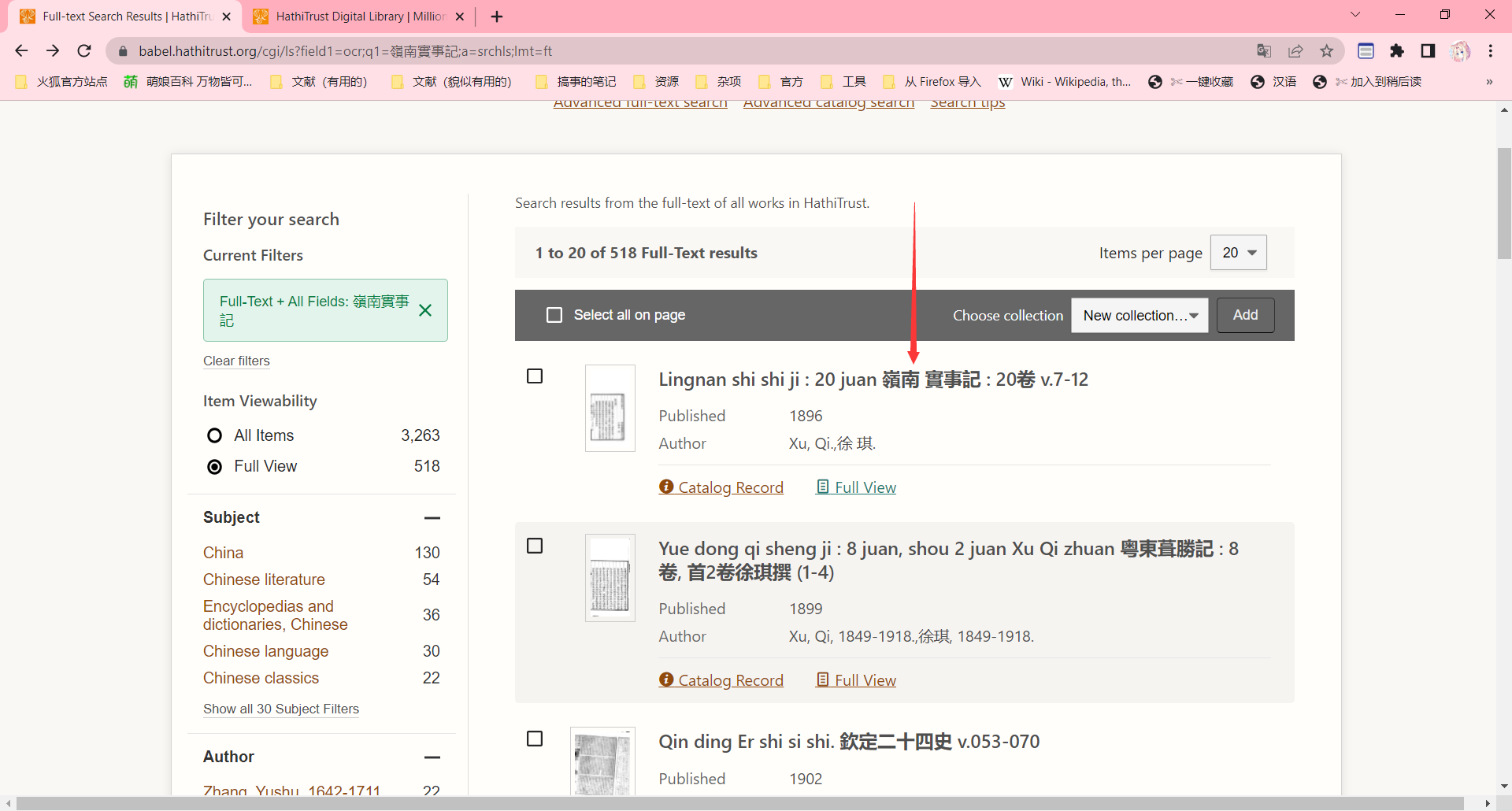
点进去你会发现左边有个下载。
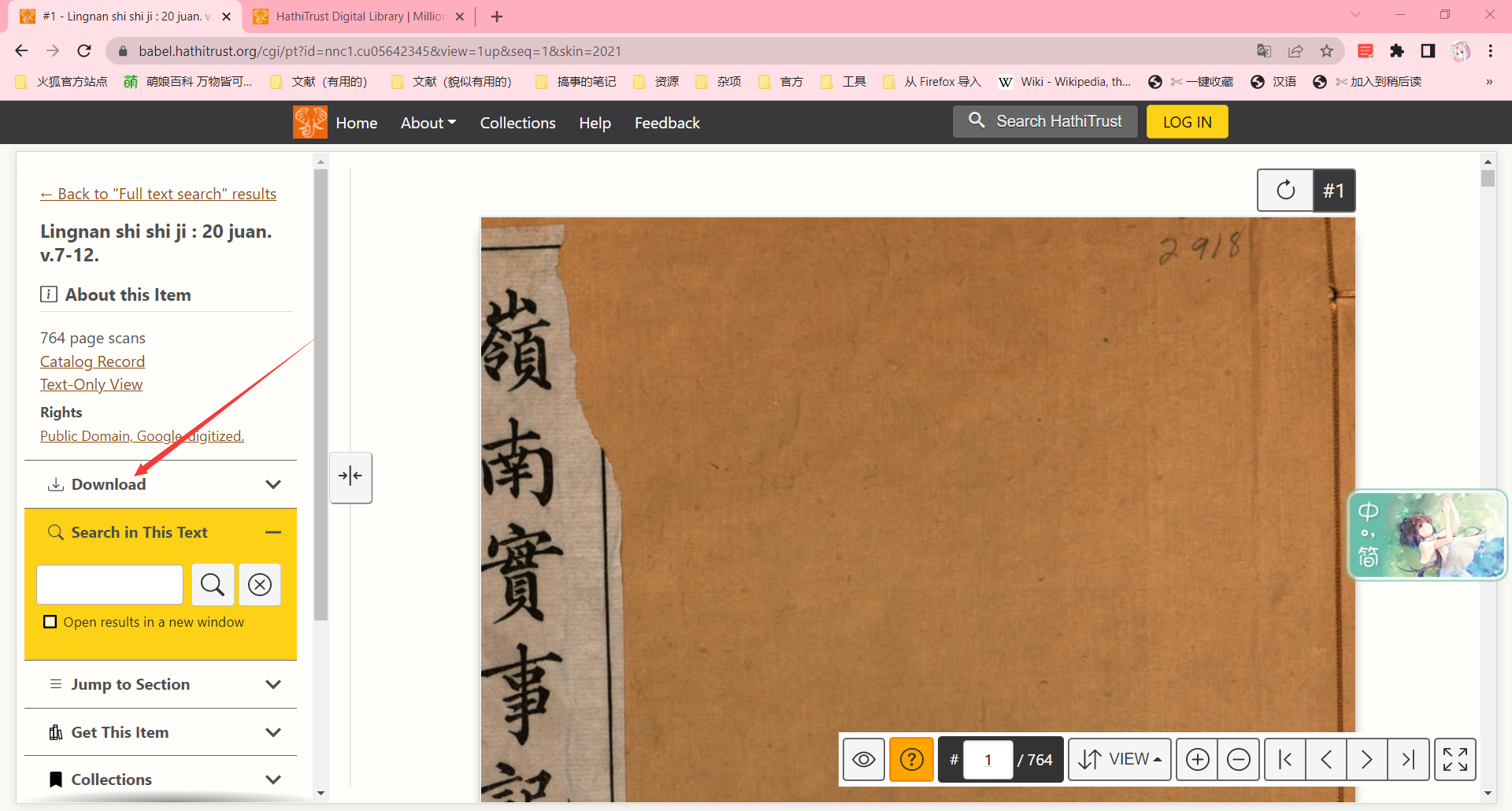
点开,自己选格式吧。
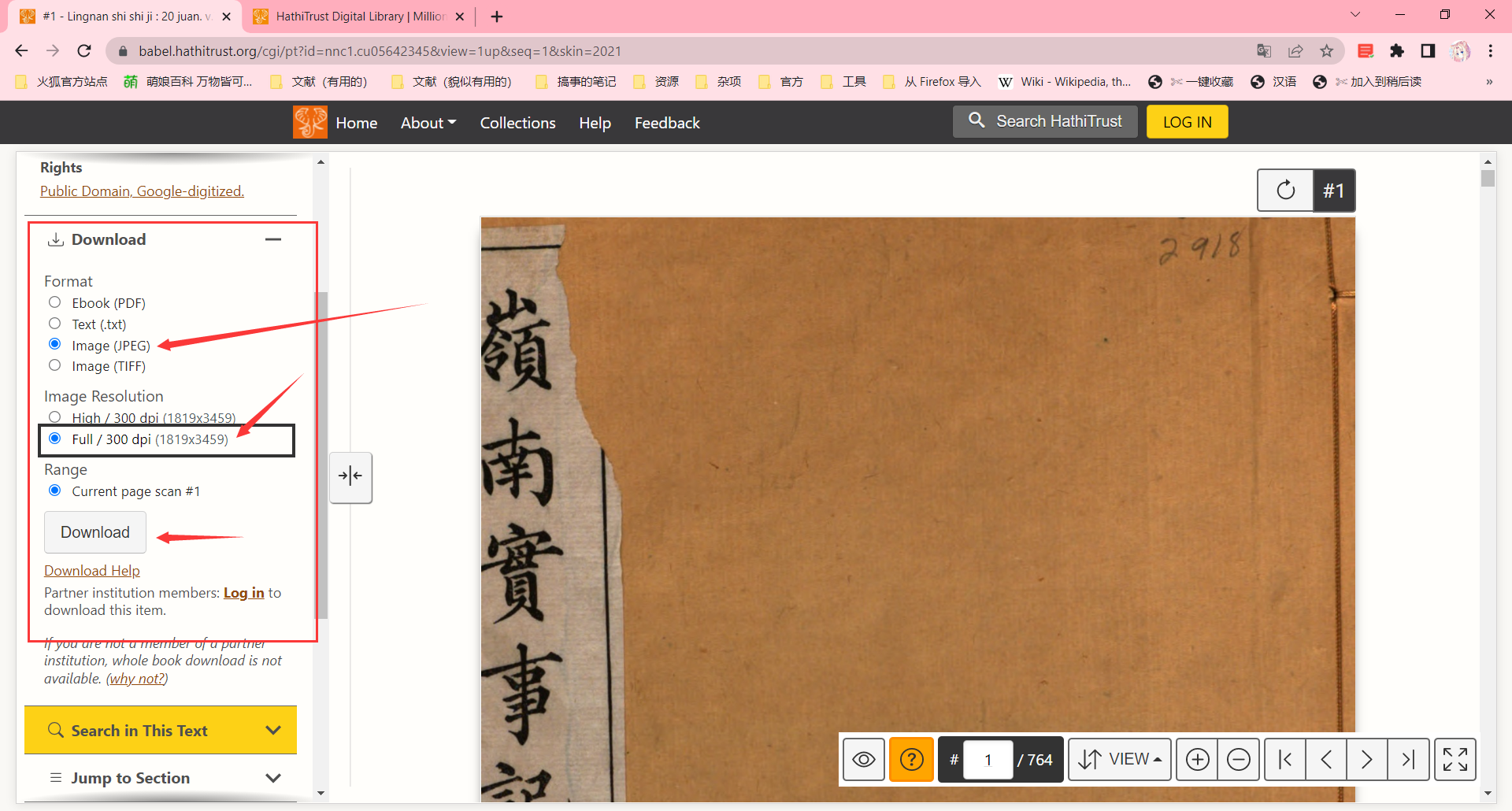
别着急点下载,先按F12,为的是抓住这个下载链接。
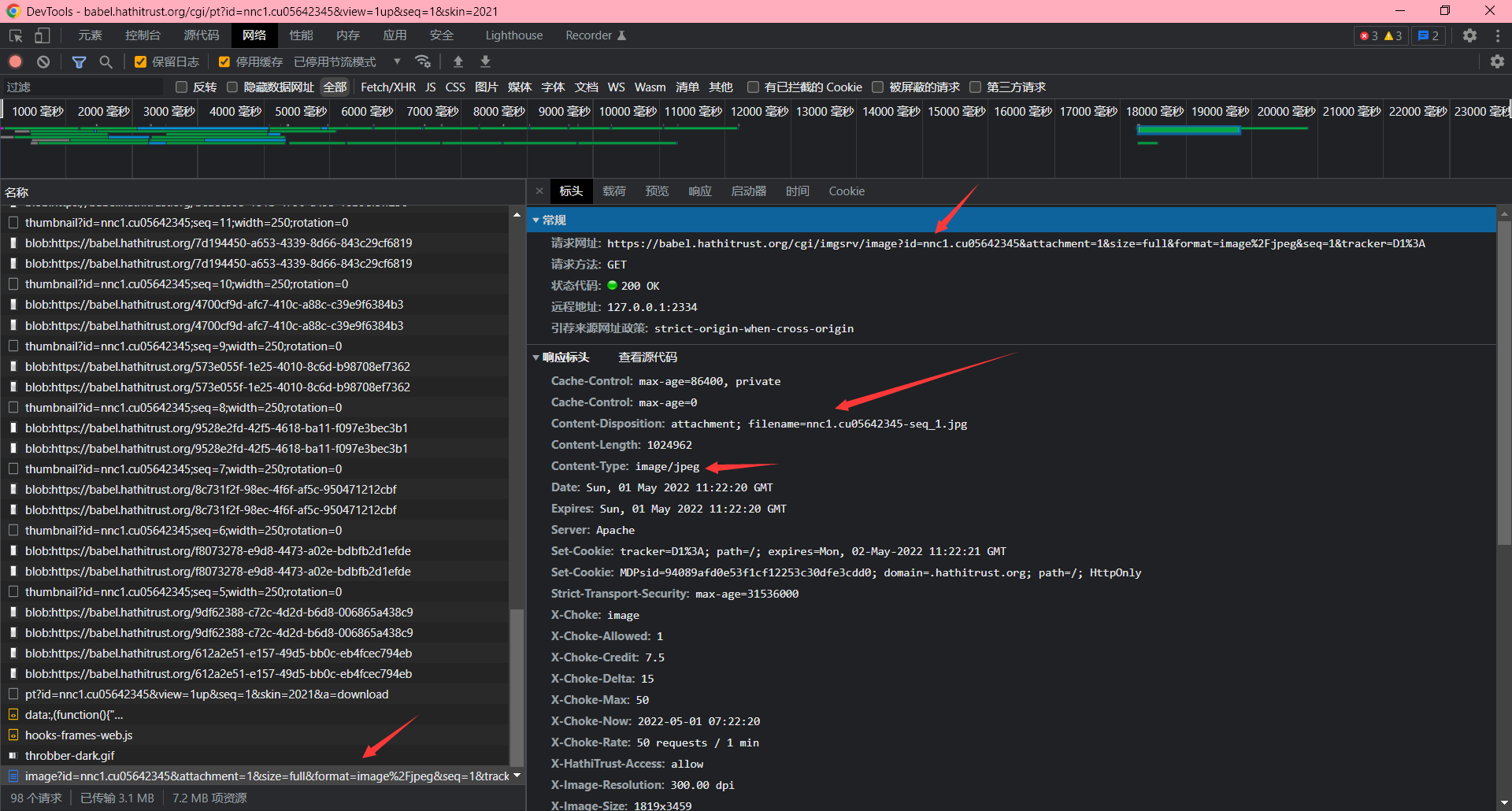
这个是浏览器的保存界面。

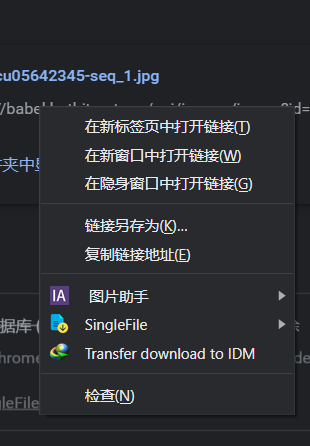
后续分析和之前两个例子一样,我这边就不写了。其实找到链接基本就完事了。如果不想按下F12,还能在底下的状态栏中点击全部显示,进入浏览器的下载内容界面。(我这边是谷歌。)
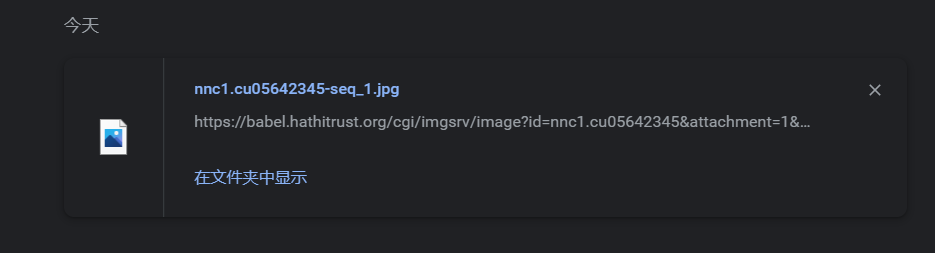
这样也有你要的链接。
结语
这个是上篇,未完待续。第一次写这么长的教程,之前我是看到四哥分享了一个他的下载教程(说实在的那个比较简易,但是调用Excel和直接让IDM翻页的原理是一样的,都是按照顺序生成。),想想我自己也折腾这些书这么久,干脆写一下个人的经验吧。真正复杂的还在后头,特别是有几个至今解决了一半但是没有完全解决的,比如说日本国立国会图书馆,以及上一篇的大藏经。等我有时间再研究一下吧。互联网上,是能看就能下。只要敢放出,就能拿到。实在不行,fiddler抓,再不行,直接内存抓包。但是,盗亦有道,声明中的内容,更像是君子协定,看诸君的经济基础吧。有问题留言或者直接联系站长。