本文最后更新于 1525 天前,其中的信息可能已经有所发展或是发生改变。
需求
1. Python相关知识和配套工具。
2. 网页分析能力
分析
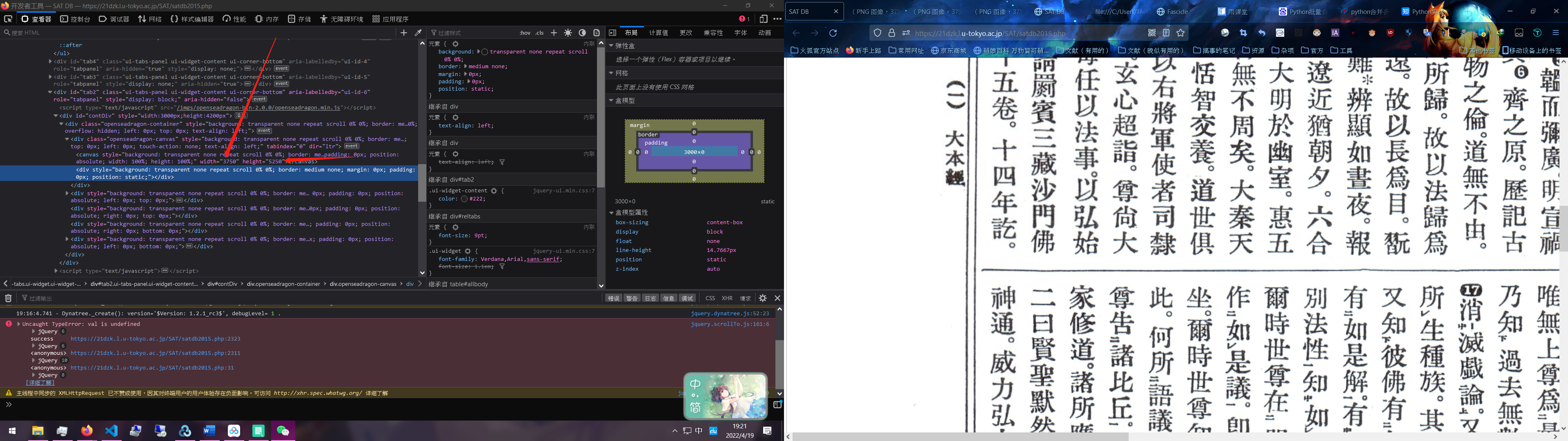
原网页是这个样子的:
2015版大藏经。
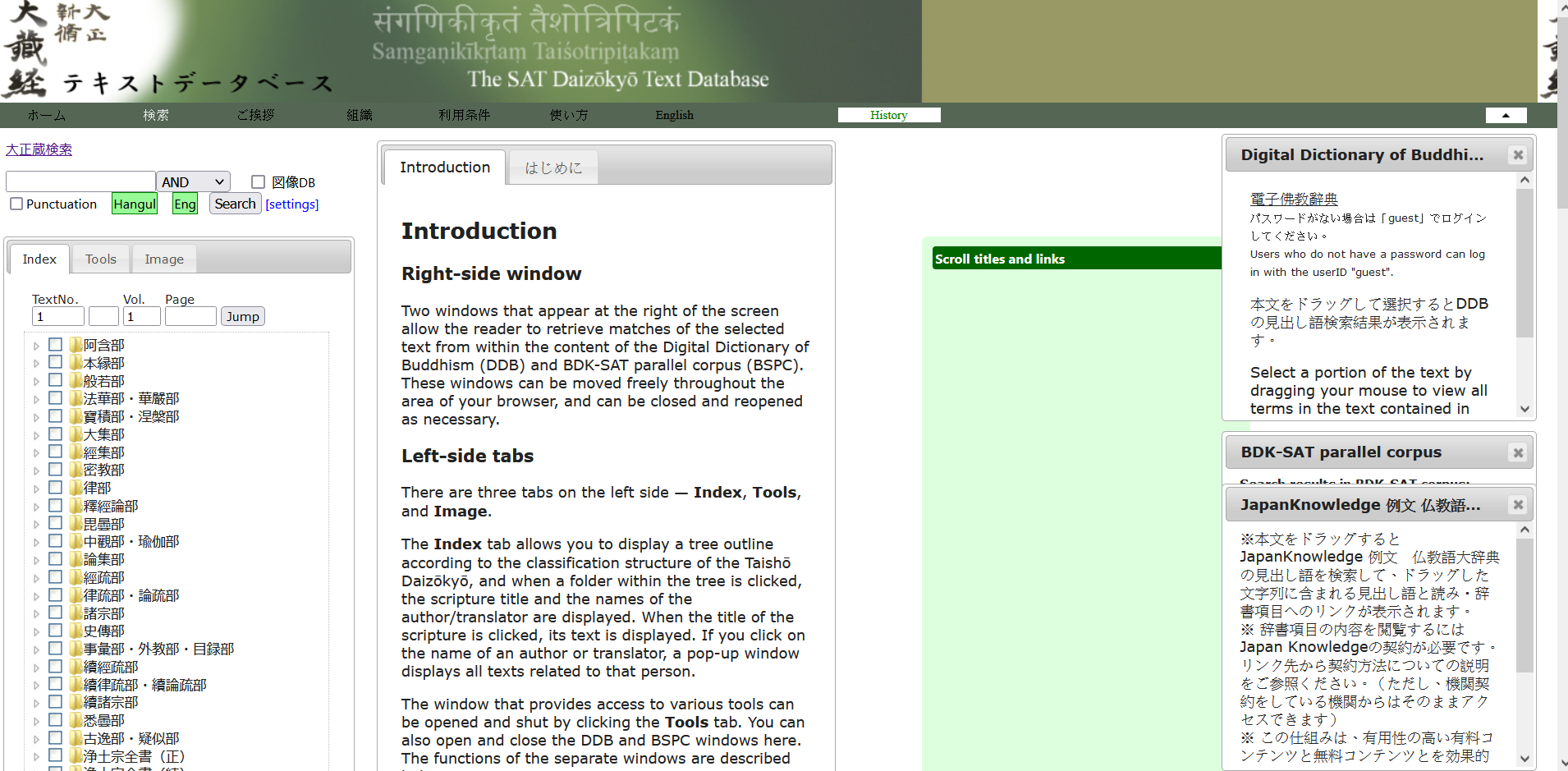
我们要的是这个框框里面的。
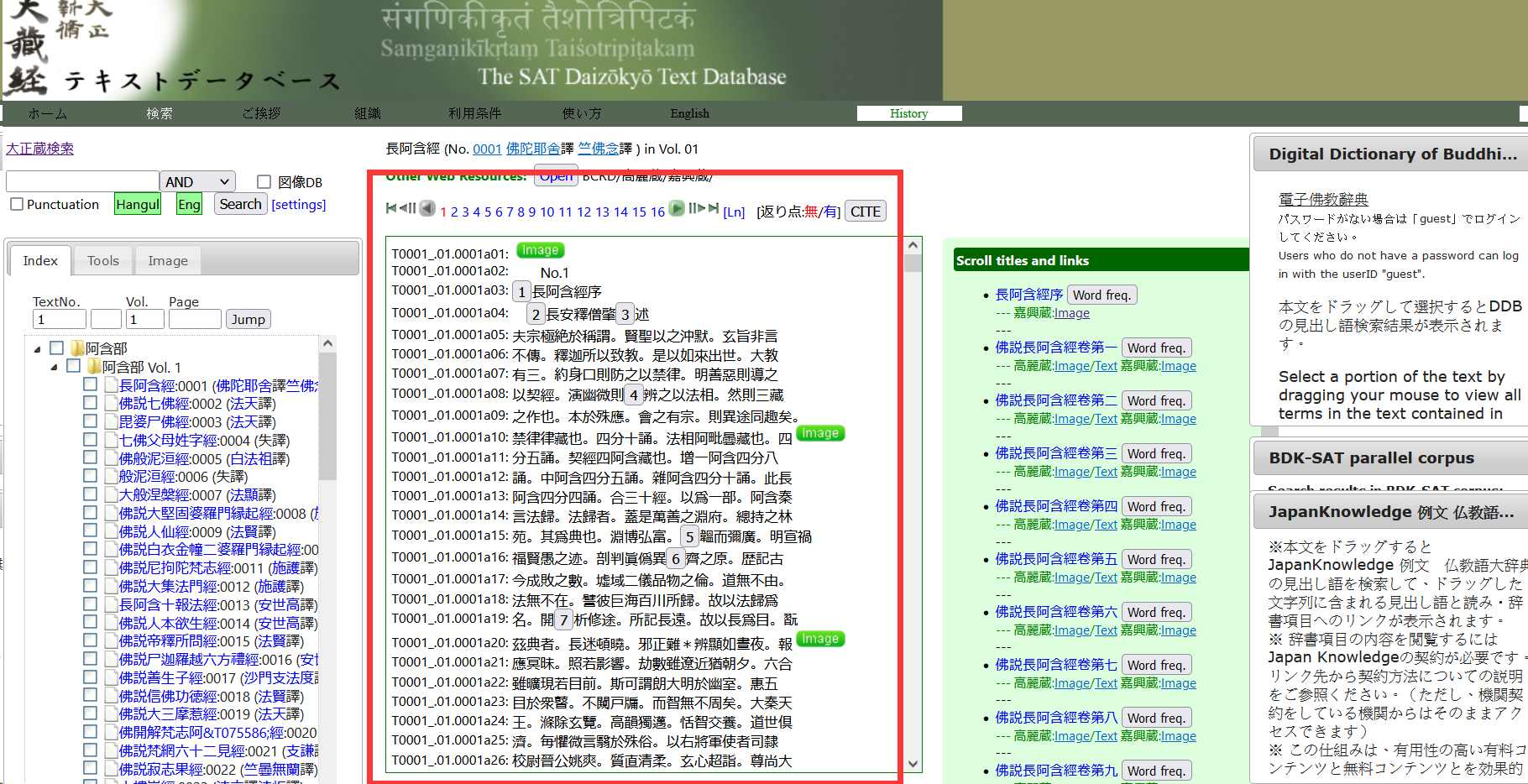
这样好办了,F12开始分析整体网页。
找到我们要的链接。

https://21dzk.l.u-tokyo.ac.jp/SAT/satdb2015.php?mode=detail&ob=1&mode2=2&mode4=&useid=0001_,01&_=1651393882728
分析链接,你就会发现有些地方是可以不用的,有些地方是必须都要的。
https://21dzk.l.u-tokyo.ac.jp/SAT/satdb2015.php?
mode=(这个里面是加载什么)
&ob=1(这个未知,但是不影响)
&mode2=2&mode4=(未知,可以改改玩玩)
&useid=0001,01(这个是卷数和分卷数,我大致这样叫吧)
&=1651393882728(最后类似于一个标识码,或者token)
那样这东西翻页怎么处理呢,我们继续翻页(此处我选了另一本可以翻页的经文。
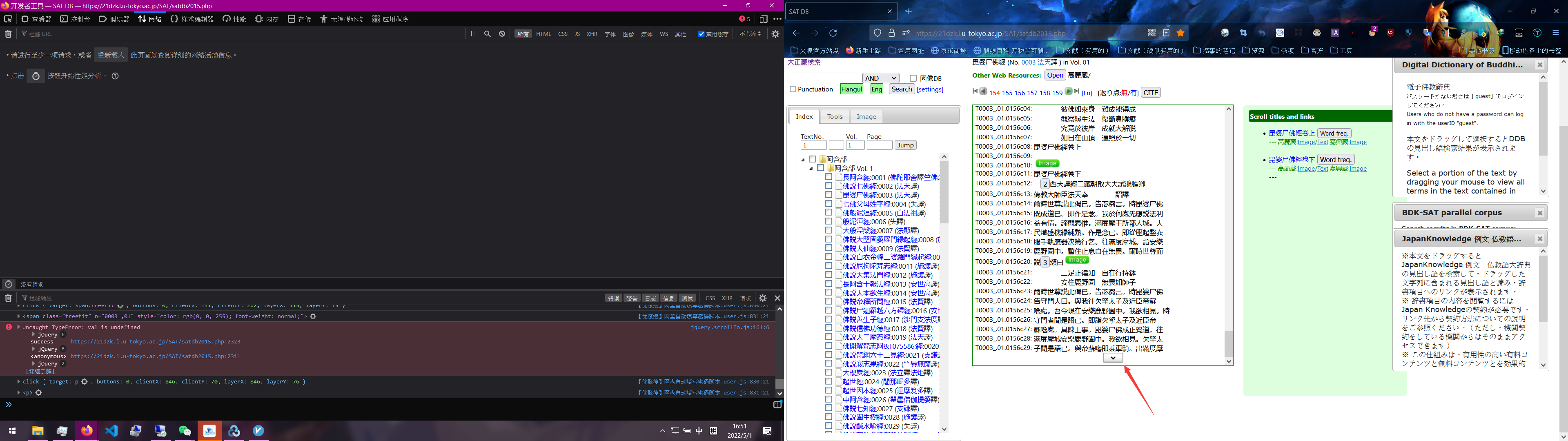
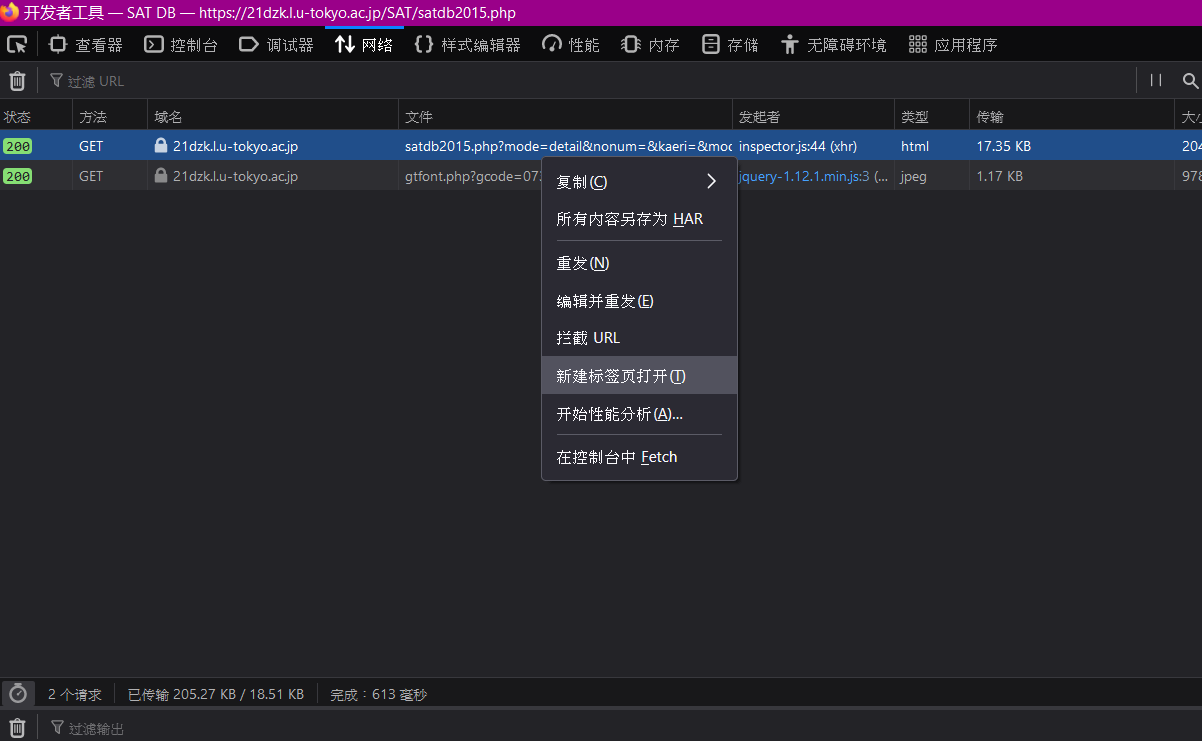
https://21dzk.l.u-tokyo.ac.jp/SAT/satdb2015.php?mode=detail&nonum=&kaeri=&mode2=2&ob=1&mode4=&useid=0003_,01,0157a01
你会发现多了东西,多了尾巴对吧,那边就是用来控制页数的,自己改改玩玩就知道了。
开干
事实证明,最开分析网页源代码是非常有必要的,请直接在2015版大藏经右键查看网页源代码,然后往下翻,就可以发现所有书的标签,根本不用去写双循环生成器,而且还会出现找不到标签的情况。
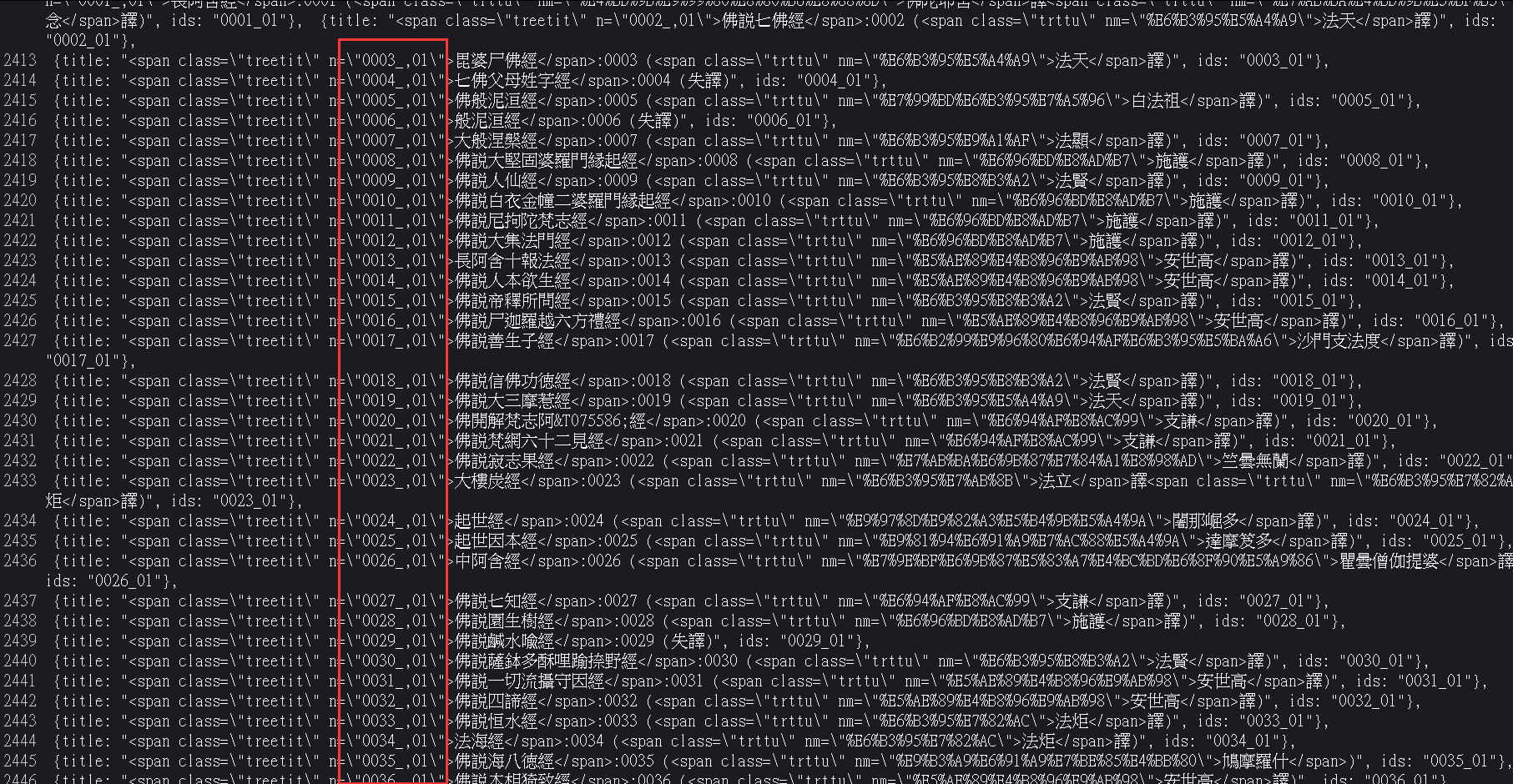
至于怎么拿出红色框框的东西请EmEditor+正则。
我们要的东西就拿的差不多了,直接上代码。或许我少写了一点点注释,多引用了一些库。最后是进行了一个对比前后文件大小再删除相同大小文件的过程。别问我为什么不直接对比MD5 SHA1 哈希,这些鬼东西全部都不一样,但是文件内容又是一样的。而Python用str比较文件内容必须要完全一致才行,所以无奈选择这种先存再删的方法。
import itertools
import requests
import urllib.request
import time
import os
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
for line, pages in itertools.product(open("biaoqian.txt"), range(1,1500)):
# line是读出来的卷,pages是页数。bp是上一页,bp2是上两页。相当于N-1&N-2
bp = pages -1
bp2 = pages - 2
# 把两个的值算出来,为的是比较前后文件大小。
line = str(line) # str化
line = line.replace("\n", "") # 去掉换行符
pages = str(pages) # 同上
bp = str(bp)
bp2 = str(bp2)
pages = pages.zfill(4) # 增加0000
bp = bp.zfill(4)
bp2 = bp2.zfill(4)
print(bp,bp2)
# print(line)
# print(pages)
url = line + "," + pages + ".html"
burl = line + "," + bp + ".html"
burl2 = line + "," + bp2 + ".html"
# 以上分别是 N N-1 N-2个文件的名字,别问为什么不直接N 和N-1, N还没创建。好像可以不用这样
print(burl,burl2)
print(url)
rurl = "https://21dzk.l.u-tokyo.ac.jp/SAT/satdb2015.php?mode=detail&ob=1&mode2=2&mode4=&" + "useid=" + url
# print(rurl)
if os.path.exists(burl2) == True & os.path.exists(burl) == True:
print("33243")
burlinfo = os.stat(burl)
burlinfo2 = os.stat(burl2)
burlinfo = burlinfo.st_size
burlinfo2 = burlinfo2.st_size
print(burlinfo,burlinfo2)
if burlinfo == burlinfo2:
print("equal")
# os.remove(url)
# print(url, "File removed successfully")
os.remove(burl2)
print(burl2, "File removed successfully")
os.remove(burl)
print(burl, "File removed successfully")
continue
else:
print("write")
else:
print("????????????")
# dic = {
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36',
# }
# html = requests.get(rurl,headers=dic)
# print (html.text)
html = urllib.request.urlopen(rurl).read()
def saveHtml(file_name, file_content):
with open(file_name.replace('/', '_'), "wb") as f:
f.write(file_content)
print("200")
saveHtml(url, html)
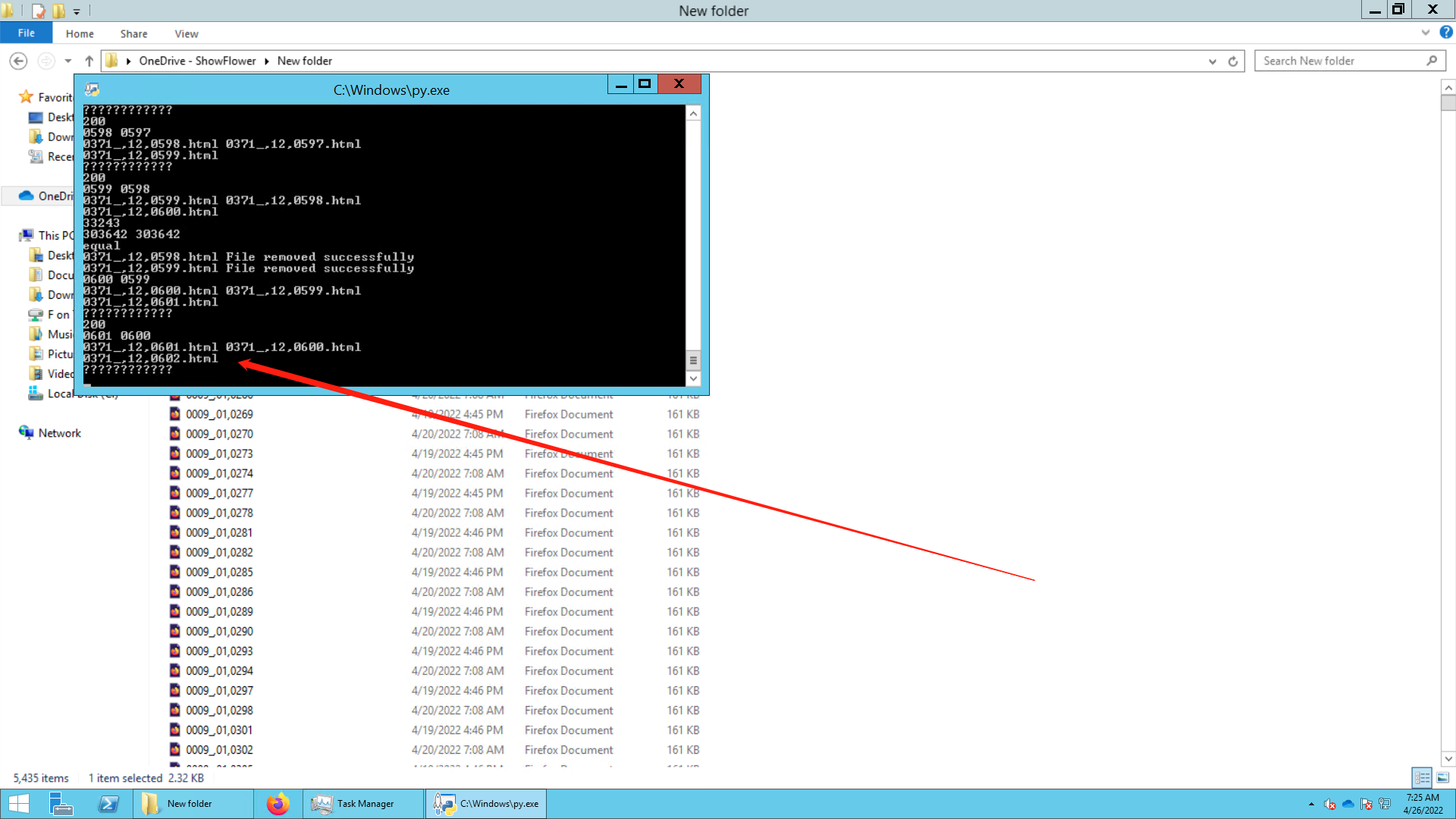
中间的很多过程我省略了,这东西的语码转换没那么容易。而且最开始我以为是直接整个站抓,就上IDM了,事实证明不可,还是直接抓文本吧。
这个是丢我服务器上爬的图,现在应该快620卷了。
关于图像
这部分没那么好搞,需要手动调节框框放大,我给个例子吧。这图能不能加载出来还是个问题,有点大。(我不管我网站流量了,放原图。)