前接上文《如何高效研究——搜索篇(上)》
且说至本地搜索库的注意事项,接着就是在线库了。
5、爱如生、鼎秀、雕龙等
笔者准备放在一起进行说明,这些是商业库的代表,也是笔者学校没买的库。那么到底要不要花这个钱,在哪花就成了问题。你说贵嘛,也贵,但是相对一篇论文来说就还好啦。目前淘宝都有售卖,我没试过,不好说。有些官方有售卖,可以看看。然后雕龙也有经销商售卖。这些东西如果实在是钱多,去买学校的license,也是一样的效果。但是怎么说呢,他们都是企业,是以盈利为目的,如果没事爬了很容易出事的。
6、对岸的一些开放的库
人不能吊死在一课树上,所以上面的这些用不了怎么办呢?看看对岸的库。史语所有一个。https://hanchi.ihp.sinica.edu.tw/ihp/hanji.htm
这个库是人敲出来的,比隔壁OCR的库要好很多。我不得不羡慕他们有稳定经费去干这个事情。而且他们做了很好的异体字字典。(论坛有本地版本,可以下载使用,20G+。然后在线版本有时候无法访问,不贴链接了。)还有各种奇奇怪怪的库,如果可以访问的话去看看吧。
7、自己家门口开放的库
外人的东西好,但是根还在我们这边啊。所以有些开放的东西是可以去看看的。比如说最经典的国学大师 http://www.guoxuedashi.net/ 还有他们的子站 http://www.guoxuemi.com/ 国学迷。具体情况估计去过的人都明白,我也不多说。类似的站也有,比如说最近刚刚上线的如是古籍字典。https://dict.rushi-ai.net/
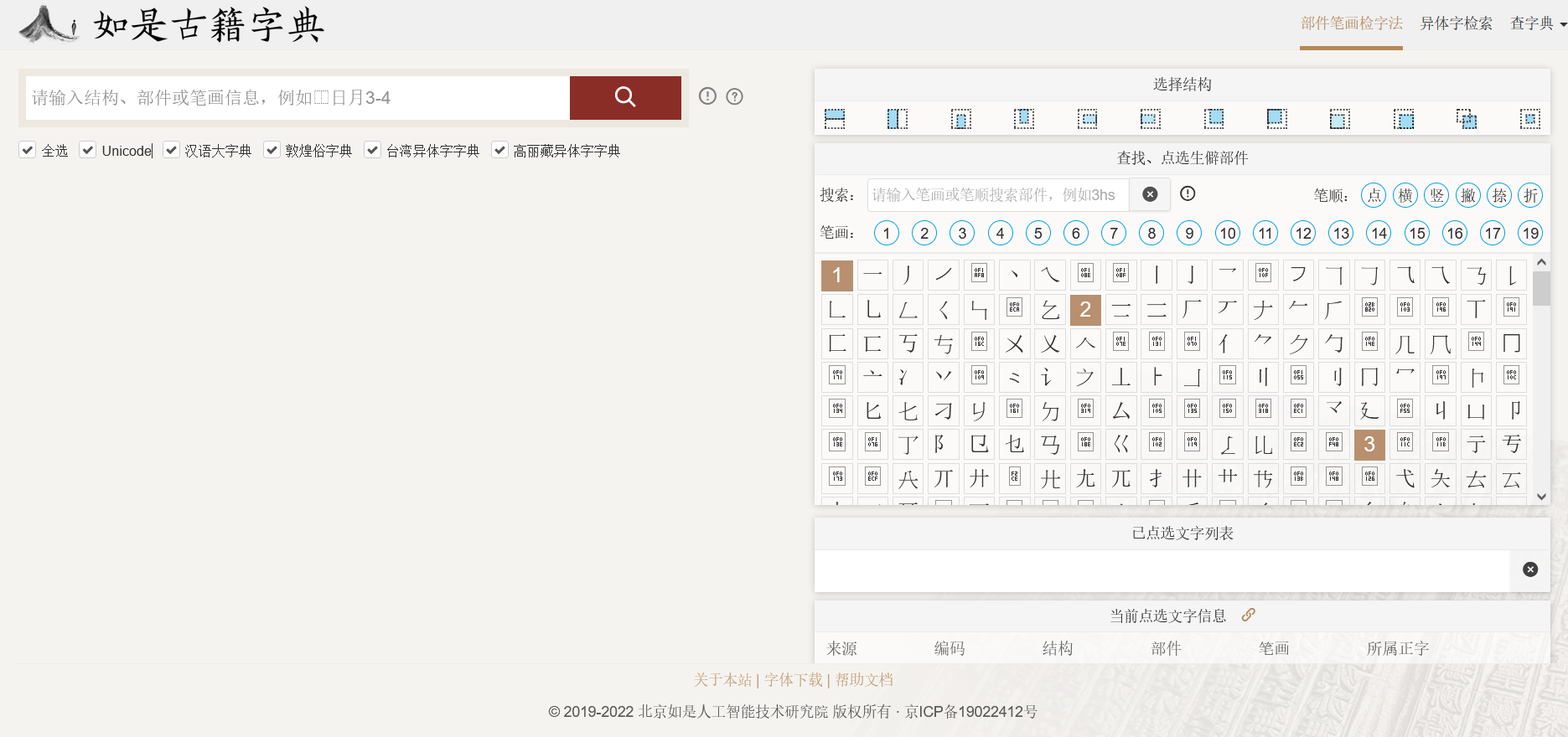
他们做的很棒了,支持汉语大字典在内的一系列字典,而且高丽藏的在线检索我是第一次见。

如果单纯是查字,可以去叶典 http://yedict.com/ 站,他们的二分查字做的很好,我自己也用了一段时间。MDICT格式的版本也有,就是没有网站更新的那么快了。
我个人在线查找使用的大概也是这些,接着说说几个文本库。
中國哲學書電子化計劃 https://ctext.org/zh 这里面有时候可以找到一些意想不到的文本,而且可以用GoldenDict搜索,但是有人无法访问。
知识图谱
https://cnkgraph.com/ 这个拿来查四库舒服多了,而且还能实现一些标引功能。
殆知阁
http://www.daizhige.org/ 都是文本,很好用。适合短时间查找且不加参考文献的。
这些库都随便搜索,但是没事别随便爬人家的库就是了。人家做个站也不容易,用着就行了。
(四)一些注意事项和衍生点
1、OCR
我只准备在这里提一下OCR(光学符号识别),后续会专门出一篇文章来讲。这个是很多时候我们获取文本的基础。相当于就是你让电脑帮你把整本书认出来(敲出来也行),而不是我们自己一个一个字去敲。这个在对付某些参考文献的时候很有用,可以快速搜索下载到的PDF的内容。
2、批量下载
我不排除很多时候真的很想看很多文章,一次性看个够。这个时候CNKI是有批量的方法,但是我也就只能提一下,出事别找我就是。去油猴找到

但是我这边要特别强调,不要没事下一大堆,上次社科院被处分的那位就是这样作死的。所以我也就是拿CNKI举个例子,其他网站请各显神通。
3、某些网站打不开(上不去)
我不解释,懂的都懂。但如果是我的站可以过来问。
4、书库
这东西同样是懂的都懂,我只能提一下链接。
https://www.duxiu.com/
https://cadal.edu.cn/
至于里面的书怎么获取,不可言传。淘宝的书怎么来的,也是一样。
5、留待更新
说不定我想起来什么了。
(五)充分利用你找到的材料
我们遇到的材料太多了,无论是纸书,电子书、语料库、期刊库还是我们自己建立的本地TXT合集。这么多东西在手上,你怎么用?不然就是鸡肋啊,放着占空间,丢掉又可惜,还是你用校园网辛辛苦苦下了那么久的。笔者准备略微论证一二,提供一点点思考,具体情况具体分析。
1、文件名
文件名所告诉你的是最基本的信息,比如说书名,作者、出版社、出版年等。比如说:
1_从四部之学到七科之学 学术分科与近代中国知识系统之创建,左玉河著,上海:上海书店出版社,2004_11417326
这是经过了重命名的,为的是一眼就能看到整个文件的基础信息。而且在用everything大范围搜索书的时候也能在多版本中找到我想要的本。节约时间啊,打开很麻烦的。
同样,文件版本号码视情况添加,特别是在写某些需要更改多版或者反复讨论敲定的材料(比如说申报书)的时候。一旦采用什么最终版本,最最最终版本,就很容易出现自己都不知道自己要交的是啥。建议可以用三位数字X.X.X(X是0-9)加到文件名的末尾。如下图所示:

这样至少自己分得清,和写文章一样,一级标题、二级标题、三级标题都要分清楚。到时候乱了套得不偿失。
2、内容为王
这个说法原本是自媒体弄出来的,但是也同样适用于我们对材料内容的利用情景。人是贪婪的,肯定不会止步于文件名,而是会好奇的打开看看里面有啥。这就涉及到对文件内容的完整利用。(写充分利用也行,差不多的意思。)
问题来了,看完了是完整利用吗?一边做笔记认真看完了算是完整利用吗?笔者认为都不完全算,都是部分。具体原因不想写了,都能和语言哲学扯到一起。再写就太多了,略过。所以笔者认为的充分利用是理解举一反三,触类旁通,还有各种现代化的分析方式。那么,我们该怎么做呢?
首先就是文本化,图片是啥,能看,能具体分析吗?连搜索都做不到啊。所以我们一开始就需要用各种手段获取文本,包括但不限于OCR、众筹敲字、直接知网下PDF、各种格式倒腾。这些需要具体情况具体分析,如果可以的话下次单独出一篇讲文本化。一定要全文搜索啊!(当然你愿意浪费资源我不介意。)
文本到手了,可以自由阅读编辑搜索了。那么第一阶段的利用就完成了,你阅读完了文本,知道在讲什么,知道对我的研究的作用了。但就止步于此了?肯定是还能往下走。是时候让计算机出马了。
比如说CITYSPACE文本分析工具,Python词频统计。总之各种文本分析文本加工遍地开花,什么向量化什么XXXX都有。包括后续还能上统计软件SPSS。这都是对文本深层次利用的方法,而且还不唯一。正因为如此,笔者也不好说什么软件最好,什么拿去发文最快,只能在此抛砖引玉了。
其实还能进一步,但是没必要了。拿去炼丹属实是超越了我们这个层面,而且我们也很难做到比大公司好的产品。所以就干脆拿人家的成品得了啊。
(六)结语
我们的研究从搜索开始,但是搜索的结果绝对不是我们的终点。无论结果再多,电脑告诉我们的东西再庞杂,都不要对信息的量产生畏惧。在经过合适的方法处理后,终究能被我们所用。信息的洪流终将被我们在家门口制伏,哺育我们的研究。到那时,我们想到并种下的小树苗都长成参天大树,荫庇后人。