前言
上次写搜索已经是500多天之前了,事实证明技术也有了新的发展。所以,我决定重新写一下有关于搜索的文章,也作为我自己的记录。同时,我自己的原则是其他人讲的比我好就用其他人的,也省的我重复造轮子。
注意
- 本机系统为WIN10/11最好,WIN7我不排除会出现什么奇奇怪怪的问题,同时我现在也没有WIN7的测试环境。
- 对电脑配置有一定的要求,如果在某些操作执行的时候较慢,可以考虑换电脑了。主要是搜索这个操作本身就很消耗资源。简单来说,就是搜索时,电脑需要做很多工作,这会消耗它的能力和存储空间。对于不太了解电脑的读者来说,可以理解为查找一本书中的信息,你需要花时间翻阅每一页,这样会占用你的时间和精力。电脑也是类似的,它需要时间和能力来处理这些搜索任务。
- Linux用户就自己研究吧,不如搭建个ES服务器或者直接上这个。https://github.com/ndl-lab/tugidigi-web (既然都用Linux了,自己折腾一下未尝不可。)
- 需要读者自己有一定的按图索骥能力。
- 请仔细阅读完全文后进行操作。
何为本地搜索
“本地搜索”通常指的是在用户的个人计算机或设备上进行的搜索活动,不依赖网络资源,而是搜索设备内部的文件、应用程序、设置等数据。这种搜索方式常见于操作系统或个别软件内建的搜索功能。
简单说明就是:自己在电脑上用软件进行搜索,不通过网站。如何实现本地搜索
我们的搜索并不仅仅是搜索文件名,还需要对文件的内容进行检索,这才是一个完整的本地搜索。【此处不对搜索和检索进行细分,统一为一样的词。(语境义)】
文本化
原因显而易见,此处不表。我之前有过一些文本化的论述,但是可能不够具体,现重新给出。
横排文件
相对于我们日常阅读的书籍,可以一律使用ABBYY处理。但是,ABBYY并不是全能的,也就是不一定文件中的所有字符都可以被识别,这个问题的解决方法我会在后文综合给出。
丢个转来的百度云链接吧。转自 https://www.lke0.cn/thread-4817-1-1.html 和 http://bbs.wuyou.net/forum.php?mod=viewthread&tid=437103
链接: https://pan.baidu.com/s/1_TbInH-7MJCUjB5XluNlkg?pwd=5mbb 提取码: 5mbb
ABBYY使用方法参考 https://www.abbyychina.com/zhishiku/处理过程
安装软件
安装个啥啊,我转来的是单文件,点击就行了。
正常使用
首先,都是中文界面,应该是看的懂的。后续参考官方教程。(记得往下翻)
https://www.abbyychina.com/zhishiku/abbyy-pinfg.html
https://www.abbyychina.com/zhishiku/abbyy-oisfb.html
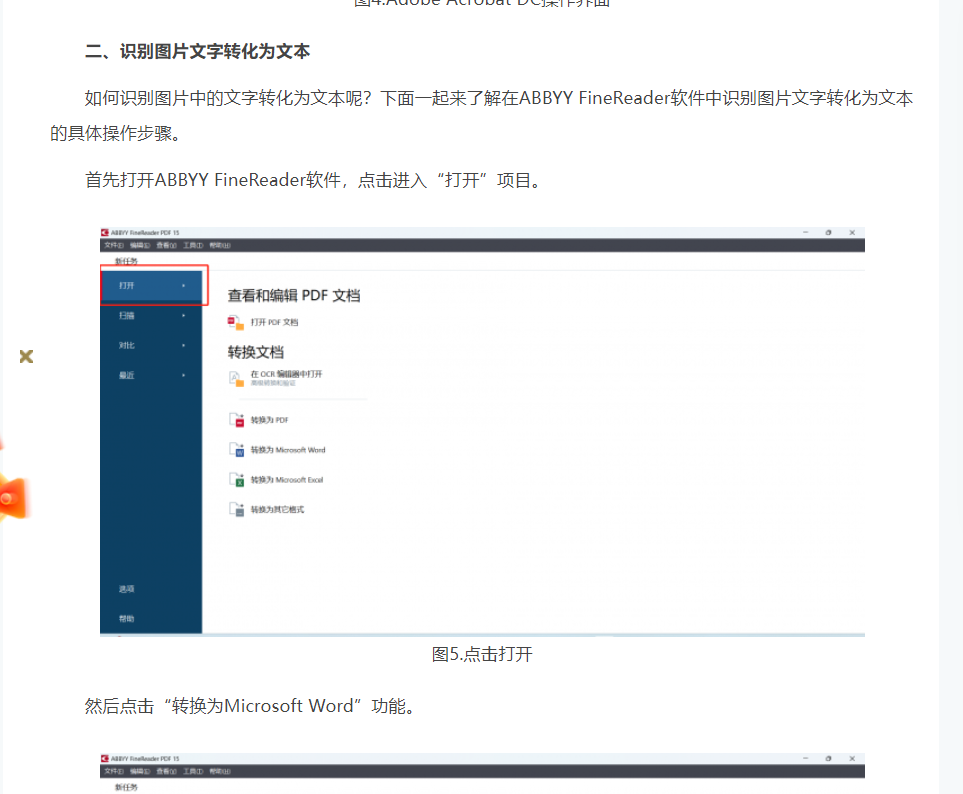
随手截了个图。
如果刚刚接触这个软件的读者请仔细阅读上面两篇教程,应该可以学会基础的使用方法了。这个是视频教程,也可以参考,我倒是觉得视频教程更加详细一点。https://www.bilibili.com/video/BV1Dw4m1i7p6/
更多的内容就请自行上网搜索学习吧,B站的视频也可以多看看。我的建议是处理成双层PDF。参考下面官方链接吧。https://www.abbyychina.com/FRshiyongjiqiao/abbyy-jjjg.html竖排文件
竖排印刷体
ABBYY也可以做,参考下面的视频。
https://www.bilibili.com/video/BV1tT4y1L7JZ/古籍
这一块有一些事项需要先进行说明。

- 这可能需要付费和短暂脱离本机的范畴。
- 草书识别目前一言难尽,所以折腾跋文的读者可以
让本科生作为劳动力想办法人工敲出来。(估计到这个份上自己也要看一遍材料吧。) - 如果已经有文本出现就去找文本即可,别重复造轮子。(下一篇文章会出现各种古籍库)
- 如果自己要整理出版请自己敲一遍,对自己负责。
- 尽可能实现文图对照,也就是确保自己可以验证识别正确与否。(这部分就看各人的文件整理习惯。)
- 小心使用某些分辨率低于300dpi的djvu文件(类似CADAL中出现的比较糊的),很可能因为压缩算法出现原生错字情况。记住孤证不立原则。
借助网络公司服务
目前提供古籍识别的公司有很多,最好的可能还是古联(籍合网)
https://ocr.ancientbooks.cn/index
操作流程在这
https://ocr.ancientbooks.cn/help?id=0
费用自己开票报销就行了。无法报销的话就去看看其他公司的服务,有没有便宜点的。
至于别的公司,可以自己去尝试,用手中的材料进行测试,以对比最终使用什么公司的服务转换为文本到本地查阅。
我这边就不做过多的推荐了,主要是目前学界没有一个统一的测试标准,民间的标准一言难尽。书格中也有讨论。(不完全正确吧,有些说法有问题,在此不表)https://www.shuge.org/meet/topic/78721/
本机运行识别程序
是免费的,但是是要折腾的,我自认为目前本地识别率最高的程序。参考我的文章:古文免费OCR——以ndlkotenocr为例
https://tmzncty.cn/post/596/
至于之前也有别的一些,但是总感觉一言难尽。
本地全文检索软件
文件检索默认everything就行,但是全文检索软件就有讲究了。我也看到了一些讨论。
本地全文搜索工具,AnyTXT Searcher 和 BBdoc ?https://www.chongbuluo.com/thread-10453-1-1.html
比Google的搜索还好用,这个工具简直了!
https://mp.weixin.qq.com/s?__biz=MzkxNTUwODgzNA==&mid=2247518850&idx=1&sn=c6851cb23f8585395a9673ac9dd68595&source=41#wechat_redirect
神器Everything做不到操作,它们三轻松解决!
https://www.bilibili.com/read/cv20333936/
借助前人的经验和我自己的经历,总结下来就是,anytext是真的能用,也足够使用。https://anytxt.net/
具体使用方法参考官方教程,但是ANYTEXT自带的文本识别引擎肯定没有上文ABBYY好。
https://anytxt.net/anytxt-searcher-a-comprehensive-guide-to-this-free-desktop-search-tool/
但是请注意调整索引位置,不然C盘会满。同时使用机械硬盘的读者可以换个固态硬盘存放索引。参照这个链接进行调整,往下翻就行。
https://post.smzdm.com/p/a5olp3ol/
同时https://www.sysadm.cc/index.php/xitongyunwei/940-files-are-piled-up-like-a-mountain-but-you-are-still-searching-for-keywords-with-ctrl-f-quickly-learn-about-the-efficiency-tool-anytxt-searcher 参考这个链接,对索引的频率进行调整。我顺手截了个图。
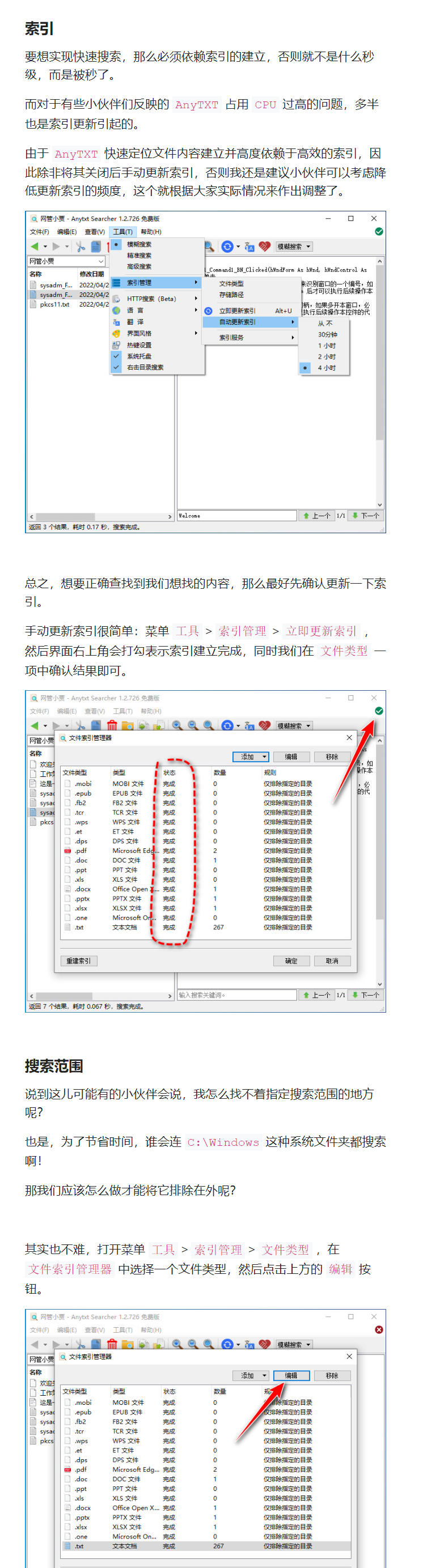
其实这些全文搜索软件的原理就是把所有文本都存储到他本地的数据库(主要是ANYTEXT没有开源所以我猜测他用了sqlite等,记录了文件位置、文本内容、文件格式等信息),这样就会造成索引较大。只能说二者不可得兼,要么占用内存要么占用本地磁盘空间。
结语
这样一来,我们就可以实现本地的全文检索以及多种文件类型的检索啦。但很明显,这只是最基础的检索,也就是一一对应的方式。并没有实现语义级别的检索。所以当我们的识别出现错误的时候,请使用周围的文字进行检索,或者开启模糊检索。并且做好有可能搜不到的心理准备。(巧妇难为无米之炊)
附言
知网下载记得去下PDF,不知道怎么下的就去搜索。别天天下CAJ,这种垃圾格式无法纳入上文全文检索领域。请一开始就下载PDF。同时结合文献管理软件进行重命名。(比如说endnote和zotero等)
至于都是TXT文件的情况下,可以考虑EmEditor,但是很消耗电脑内存就是了。(我只能提一句,因为不算是什么特别方便的方法,但是EmEditor是个好软件。)