文章目录[隐藏]
请仔细在电脑上阅读完原文再操作,同时如果有不懂的请及时询问chatgpt等ai,并且上网查询。也可以发邮件联系我。(请查看上面联系站长)顺便感谢一下他们开源出GPU版本的模型供我们使用。
简介
这是一个利用NDL古典籍OCR技术将古典文献资料转换为文本数据的应用程序。版本3相较于之前版本在汉籍资料的布局识别性能上有所提升,特别是针对江户时代之前的和古书籍、清代之前的汉籍等文献资料。该程序由国立国会图书馆独立开发,采用了从相关项目中获得的经验教训和人文信息学领域中积累的数据资源。通过CC BY 4.0许可发布。Github链接 https://github.com/ndl-lab/ndlkotenocr_cli
注意
还是请详细阅读并判断自己实力后操作,我尽可能写的详细一点。本来是打算录制的,但是众所周知wayland的安全性让我的obs无法录制屏幕,只能录制窗口,但是这样的话会缺少一些操作。所以见谅,估计这也是全网第一篇ndlkotenocr教程。
先把我的系统配置写在下面吧,具体要点我分开叙述。
Operating System: Ubuntu 22.04
KDE Plasma Version: 5.24.7
KDE Frameworks Version: 5.92.0
Qt Version: 5.15.3
Kernel Version: 6.5.0-35-generic (64-bit)
Graphics Platform: Wayland
Processors: 32 × AMD EPYC 7302 16-Core Processor
Memory: 125.7 GiB of RAM
VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti Rev. A] (rev a1)硬件
根据github的代码,是需要NVIDIA的GPU才能运行的,其实理论上也可以改成cpu运行,但是在第一步构建docker镜像的时候就可能过不去。(具体下面会详细叙述。)至于对显存的需求应该是较小,我觉得现在的N卡普遍应该是2G起步吧,完全足够运行的。(后文会说明)
系统
我是用ubuntu系统构建的,如果是win系统请参照wsl2的配置来构建,具体查一下吧,操作不算难,都有视频教程什么的。
个人
有一定的命令行基础和英文基础,同时愿意动手去折腾。(有可能消耗一个下午的时间)
网络
这个就懂得都懂了,后文我会详细提到。我是用旁路由解决了这个问题。
开始前的准备
git安装
sudo apt updatesudo apt install gitDocker安装(ubuntu)
安装 Docker 在 Ubuntu 上是相当简单的,一定要全程在root下运行。反正一行一行执行过去即可。自己判断是否要换源。
下面是一些基本的步骤:
- 更新包列表:
sudo apt update- 安装必要的软件包,以便允许 apt 通过 HTTPS 使用存储库:
sudo apt install apt-transport-https ca-certificates curl software-properties-common- 添加 Docker 的官方 GPG 密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -- 添加 Docker 的稳定存储库:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"- 再次更新 apt 包列表:
sudo apt update- 确保从 Docker 存储库中下载的是正确版本的软件包:
apt-cache policy docker-ce你应该会看到一个输出,显示可用的 Docker 版本,以及将要安装的版本。
- 安装 Docker:
sudo apt install docker-ce- 验证 Docker 是否安装成功:
sudo systemctl status docker这将显示 Docker 服务的状态。
- (可选)添加你的用户到 Docker 组:
这样可以让你在不使用 sudo 的情况下运行 Docker 命令。
sudo usermod -aG docker $USER- 重新登录:
退出当前会话并重新登录,以使用户组更改生效。
- 验证 Docker 安装是否成功:
docker --version这应该会显示 Docker 的版本信息。
现在,Docker 已经成功安装在你的 Ubuntu 系统上了。你可以使用 docker 命令来管理 Docker 容器和镜像。
附:docker常用命令。
Docker 是一个流行的容器化平台,以下是一些常用的 Docker 命令:
docker run: 运行一个容器。
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]docker build: 根据 Dockerfile 构建一个镜像。
docker build [OPTIONS] PATH | URL | -docker pull: 从 Docker 仓库中拉取一个镜像。
docker pull [OPTIONS] NAME[:TAG|@DIGEST]docker push: 将一个镜像推送到 Docker 仓库。
docker push [OPTIONS] NAME[:TAG]docker ps: 列出正在运行的容器。
docker ps [OPTIONS]docker images: 列出本地的镜像。
docker images [OPTIONS] [REPOSITORY[:TAG]]docker stop: 停止一个或多个正在运行的容器。
docker stop [OPTIONS] CONTAINER [CONTAINER...]docker start: 启动一个或多个停止的容器。
docker start [OPTIONS] CONTAINER [CONTAINER...]docker restart: 重启一个或多个正在运行的容器。
docker restart [OPTIONS] CONTAINER [CONTAINER...]docker exec: 在运行的容器中执行命令。
docker exec [OPTIONS] CONTAINER COMMAND [ARG...]docker rm: 删除一个或多个容器。
docker rm [OPTIONS] CONTAINER [CONTAINER...]docker rmi: 删除一个或多个镜像。
docker rmi [OPTIONS] IMAGE [IMAGE...]docker inspect: 显示有关容器或镜像的详细信息。
docker inspect [OPTIONS] NAME|ID [NAME|ID...]docker network: 管理 Docker 网络。
docker network [OPTIONS] COMMAND [ARG...]
这些只是 Docker 命令的一部分。你可以通过运行 docker --help 来获取完整的命令列表和帮助信息。
Docker容器使用NVIDIA GPU
参考
https://cloud.tencent.com/developer/article/1924792
为了防止他人文章丢失,我还是复制主要内容如下,请参照命令执行即可。同时对他表示感谢。
GPU驱动
添加 NVIDIA 驱动程序
在继续进行 Docker 配置之前,请确保您的主机上的 NVIDIA 驱动程序正常工作。您应该能够成功运行nvidia-smi并看到您的 GPU 名称、驱动程序版本和 CUDA 版本。
关于如何更新驱动,请问一下gpt,然后可以的话记得提前创建系统快照并打开ssh以防止崩。(实际上我没遇到那样的问题)我的建议还是升级到最新再进行下面的操作。并且记得选择nvidia-server版本的驱动。一切操作完成后运行命令如下图所示。
nvidia-smi
添加NVIDIA Container Toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list安装nvidia-docker2
sudo apt-get update
sudo apt-get install -y nvidia-docker2重启 Docker
sudo systemctl restart docker使用 GPU 访问启动容器
由于默认情况下 Docker 不提供您系统的 GPU,您需要创建带有--gpus硬件标志的容器以显示。您可以指定要启用的特定设备或使用all关键字。
该nvidia/cuda 镜像是预先配置了CUDA二进制文件和GPU的工具。启动一个容器并运行nvidia-smi命令来检查您的 GPU 是否可以访问。输出应与您nvidia-smi在主机上使用时看到的相符。CUDA 版本可能会有所不同,具体取决于主机上和所选容器映像中的工具包版本。
下面的11.4.0和20.04照着上面你的nvidia-smi改
sudo docker run -it --gpus all nvidia/cuda:11.4.0-base-ubuntu20.04 nvidia-smi我的命令就是
sudo docker run -it --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
开始部署ndlkotenocr
在开始之前,我希望大家看看nld的github主页https://github.com/ndl-lab ,然后分清楚。
ndlocr_cli是老版本,也就是V1 2,然后ndlkotenocr_cli
是新的版本,也就是V3。同时旁边有个tugidigi-web估计很好玩,我什么时候来试一下。

下面大部分照着https://github.com/ndl-lab/ndlkotenocr_cli
来,我用方括号在全文翻译下做好注解。跟着步骤往下走即可。
NDL古典典籍OCR应用程序(版本3)
这是一个提供利用NDL古典典籍OCR进行文本化的应用程序的存储库。
NDL古典典籍OCR是一种用于从数字化图像中提取文本数据的OCR,可用于江户时代及以前的日文古籍,清朝以前的中文古籍等古典典籍资料。
该程序是国立国会图书馆基于2023年度OCR相关项目的经验,以及NDL Lab在人文信息学领域的研究成果,结合过去积累的数据资源而自主开发的。
自从2023年8月发布的版本2以来,汉籍资料的布局识别性能已经有所提升。
有报道称,在汉籍资料的文本化过程中,版本2的布局识别性能相比版本1有所下降。尤其是当使用NDL古典典籍OCR进行汉籍资料的文本化时,建议升级到版本3。
参考文献:永崎研宣等,OCR 的高精度化を踏まえたデジタル学術編集版の新展開。じんもんこん 2023 論文集,2023,2023: 177-182。(外部链接)
在改善阅读顺序整理功能的性能时,我们利用了从2024年度OCR相关项目中获得的经验。
请参阅古典典籍资料的OCR文本化实验及OCR学习用数据集(大家一起翻刻)以获取有关本程序开发和改进所使用的数据集和方法的详细信息。
该程序由国立国会图书馆以CC BY 4.0许可证发布。详情请参阅 LICENSE。
如果您希望继续使用截至2023年8月发布的版本,请使用版本1。如果您希望继续使用截至2024年2月发布的版本,请使用版本2。
您可以通过修改以下代码片段中的源代码获取并继续使用:
git clone https://github.com/ndl-lab/ndlkotenocr_cli -b ver.1
git clone https://github.com/ndl-lab/ndlkotenocr_cli -b ver.2[实际上可以用,我一开始就用的是这个。]
环境设置
1. 克隆存储库
[自己调整好网络即可]
请执行以下命令:
git clone https://github.com/ndl-lab/ndlkotenocr_cli2. 更新主机的NVIDIA驱动程序
在容器内使用CUDA 11.8。
如果主机的NVIDIA驱动程序版本为:
- Linux:450.36.06或更高
- Windows:520.06或更高
请进行更新以符合您的GPU。
(参考信息)
我们在以下主机环境(AWS g5.xlarge实例)上进行了操作确认:
操作系统:Ubuntu 18.04.6 LTS
GPU:NVIDIA A10G
NVIDIA驱动程序:470.182.03
3. 安装docker
请按照上文中的说明,根据您的操作系统和发行版安装docker。
4. 构建docker容器
[这一步是最重要的,请确保你的磁盘空间足够(30G以上)和网络通畅。就我发现他获取的源很可能是国外的源,当时下pytorch都下崩了一次。同时请耐心等待并时不时盯着一下,一般来说不会出太大问题。我也不知道为什么官方不给出可以拉取的镜像反而是用这种方式,但是大概率是GPU环境难搞,所以需要根据本机来build。]
Linux:
cd ndlkotenocr_cli
sh ./docker/dockerbuild.shWindows:
cd ndlkotenocr_cli
docker\dockerbuild.bat[我补充一些图供大家参考,可以看出我崩了几次,重新执行sh就没问题了,实际上我当时没配docker的gpu环境也build好了,但是无法调用gpu就是了。]







5. 启动docker容器
Linux:
[这里我特别要提一下,别急着启动,先看看脚本有啥,实际上就是一句命令。我的建议是大家看情况改一下,有些时候是py37有些时候是38,这个自己仔细看build的输出即可。然后这个命令和v2版本不大一样,v2版本似乎可以指定显存占用,我不知道那个参数在这边能不能用。同时,请自己想办法把本地路径挂进去,别学我用wget传输图片,我是测试。]
docker run --gpus all -d --rm --name kotenocr_cli_runner -i kotenocr-cli-py37:latestcd ndlkotenocr_cli
sh ./docker/run_docker.shPS:[我当时修改后的v2启动命令]

Windows:
cd ndlkotenocr_cli
docker\run_docker.bat环境设置完成后的目录结构(供参考)
ndlocr_cli
├── main.py : 主要的Python脚本
├── cli : 存储CLI命令使用的Python脚本的目录
├── src : 存储每个推理处理的源代码的目录
│ ├── ndl_kotenseki_layout : 存储布局提取处理的源代码的目录
| ├── reading_order:存储阅读顺序整理处理的源代码的目录
│ └── text_kotenseki_recognition : 存储文本识别处理的源代码的目录
├── config.yml : 示例推理设置文件
├── docker : 存储通过Docker创建环境的脚本的目录
├── README.md : 本文件
└── requirements.txt : 必需的Python包列表
教程
[这个没啥,当linux运行照抄即可,但是记得维持文件夹的格式,相当于一定要按照这个层级体系操作,不然就会找不到文件。看图就是了。对了,图片必须要jpg]

启动后,您可以使用以下docker exec命令登录容器:
docker exec -i -t --user root kotenocr_cli_runner bash执行推理处理
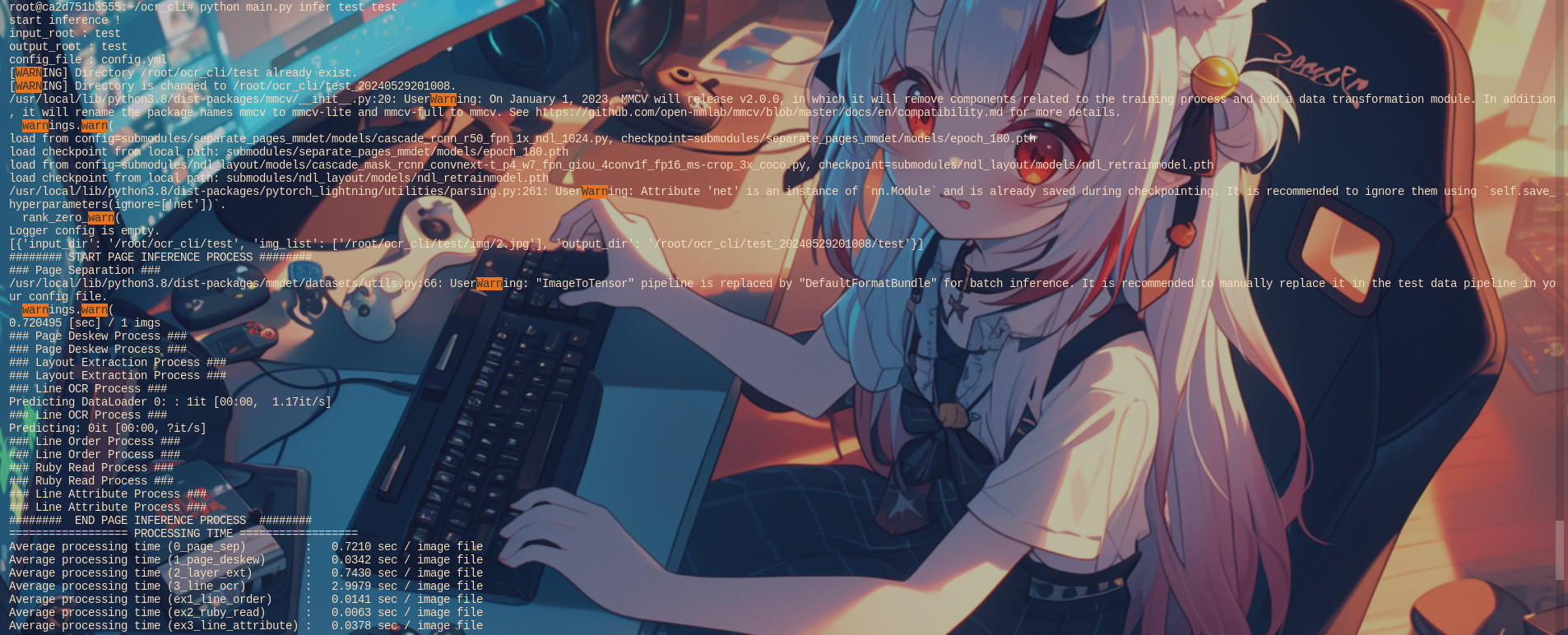
如果在input_root目录的直接子目录img下有各资料的图像目录(例如bookid1、bookid2等),则可以执行以下命令:
python main.py infer input_root output_dir执行后的输出示例如下:
output_dir/
├── input_root
│ ├── txt
│ │ ├── page01.txt
│ │ ├── page02.txt
│ │ ・・・
│ │
│ └── json
│ ├── page01.json
│ ├── page02.json
│ ・・・
└── opt.json
您可以通过修改config.yml文件的内容来更改每个模块中使用的设置值,例如权重文件路径等。
选项说明
输入格式选项
通过在执行时指定 -s b 可以处理以下输入格式的文件夹结构。
例:
python main.py infer input_root output_dir -s b输入格式:
input_root/
└── img
├── bookid1
│ ├── page01.jpg
│ ├── page02.jpg
│ ・・・
│ └── page10.jpg
├── bookid2
├── page01.jpg
├── page02.jpg
・・・
└── page10.jpg
输出格式:
output
_dir/
├── input_root
| ├──bookid1
│ | ├── txt
│ | │ ├── page01.txt
│ | │ ├── page02.txt
│ | │ ・・・
│ | │
│ | └── json
│ | ├── page01.json
│ | ├── page02.json
│ | ・・・
| ├──bookid2
│ | ├── txt
│ | │ ├── page01.txt
│ | │ ├── page02.txt
│ | │ ・・・
│ | │
│ | └── json
│ | ├── page01.json
│ | ├── page02.json
│ ・・・
└── opt.json
图像尺寸输出选项
通过指定 -a 可以在输出json中添加图像尺寸信息。
例:
python main.py infer input_root output_dir -a请注意,启用此选项会将输出json的格式更改为以下结构:
{
"contents":[
(每个字符矩形的坐标、识别字符串等)
],
"imginfo": {
"img_width": (原始图像的宽度),
"img_height": (原始图像的高度),
"img_path":(原始图像的目录路径),
"img_name":(原始图像名称)
}
}选项信息保存
在输出目录中,执行时指定的选项信息将保存在opt.json中。
有关重新训练模型的说明
截至2024年2月,我们已经公开了重新训练布局识别模型和文本识别模型的步骤。
有关布局识别模型的说明,请参阅train-layout.ipynb和cococonverter-NDLDocL。
有关文本识别模型的说明,请参阅train.py。
测试及运行情况