
siyuan作为一款笔记软件,还是有诸多不足的,但是市面上又没有什么好的替代品,就先将就着用吧。 部署方案 web服务器使用 nginx siyuan本体使用 docker 为什么使用docker部署 快速 · 几分钟就可以部署完毕 简单 · 都是基础命令,非常容易学 隔离 · 不在系统内创建文件,…
面对新事物的思考与实践:心态、成本与实操
FROM CHATGPT:
面对未知的事物,首先我们需要保持一个良好的心态。在面对挑战时,我们要用开放包容的心态去思考,去面对这一切。面对新事物,我们需要考虑其中涉及的成本问题,包括实操和总结的成本。在这个过程中,我们可以用AI来帮助我们总结,例如使用B、Y和PDF等技术,提高工作效率。
在使用新技术时,我们不需要亲力亲为,而是要对我们的用途和使用场景进行充分概括,明确我们的需求所在。评估新技术能否满足我们的需求,如果能,我们就可以继续实操;如果不能,我们可以分享给需要的人。因为有时候我们并不是不需要这些新事物,而是对它们的需求并不完全。
在评估新技术的价值时,我们可以从不同的层面来看待:圈内、行业内、整个市场或上下游供应链体系。我们要分辨新技术到底是危机还是一个变化,还要看媒体渲染的神乎其神是否合理。在面对新技术时,我们需要寻找解决方案,将我们所知道的功能和玩法相互连接,创造出更加满足自己需求的物。
我们要认识到工具的存在合理性和合法性,更要利用这些工具改善生活,尽最大可能去使用它们,创造更多价值。面对新工具时,我们需要提前具备一定的知识、能力、思维、金钱和时间等资源。如果没有,请直接学,想方设法地拥有它们,因为这是当今社会生存的本能。
在接受新信息时,我们要保持开放的态度。虽然没有人知道最终的结果,但是时间会见证一切。最后,我们需要不断地提高自己,具备面对新技术、新工具的能力。在这个过程中,我们将更好地适应这个快速发展的社会,成为一个有能力、有思考力的人。
语言-技术壁垒
利用不同语言的特点变成技术壁垒。如果说一个技术是印欧语系中出现,那么它将非常适合该语系环境下运行,但是转移到汉藏语系则会出现诸多困难。以NLP的分词为例,汉语是没有词型变化的,但是英语有。所以从英语国家传来的一系列技术需要进行本土化,这进一步增加了时间和成本。要么就是你只能服从你选择的那套技术体系。(比如说张慧和杨炳钧的《情态隐喻视阈下网络游戏话语的符号暴力研究》用的例子是英文版原神,不是中文版。)这样一来,言必称abc,怕是不大好吧。
主要问题不在语言,也在语言。这种人类创造出来束缚自己的工具终将成为一种武器。不是听不听得懂,或者说简单的文化渗透,这在二战用烂了。(参考《最后一课》)而是体系渗透,你需要的所有东西都是用我的语言写成,那么你被迫接受我的整套语言体系。即使是全部重构,也无法推翻或者完全替代。因为你的工具就是用我的语言写成的。在这个世界上,从零开始的成本比直接干掉对方高得多。
我们有没有可能打不过就加入呢?或者魔改后脱胎换骨呢?这就见仁见智了。
一些技术类文章,我想想还是丢到B站,为的是更多人可以看到,给后世参考。
https://www.bilibili.com/read/readlist/rl681758
瞎扯一下全文搜索
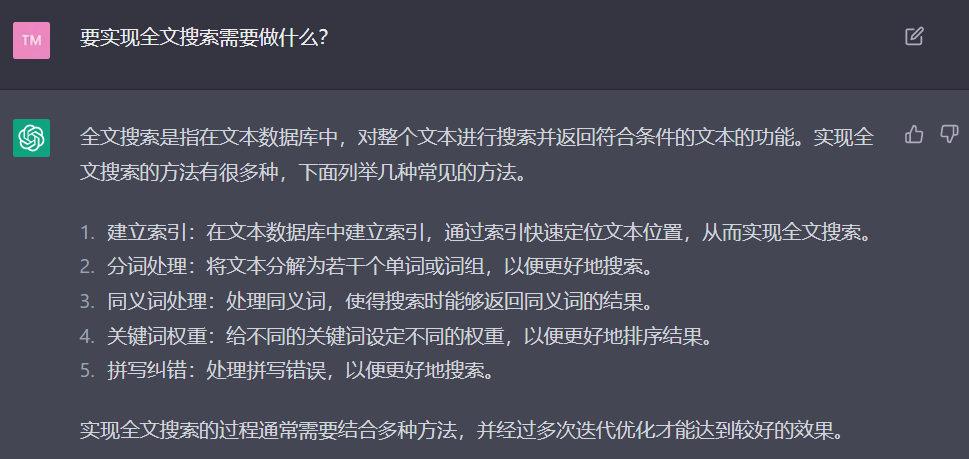
这东西本来是可以写成文章的,但是我直接谈经验比较好,而且我是喜欢本地化的。(进了自己脑子的东西才是自己的东西。)
全文搜索软件比如说ANYTXT和Archivarius3000,对于电脑配置的要求较高,除非你只进行TXT或者WORD单文件搜索,那样请随意。但是一旦涉及整个文件夹或者整个机子的文本搜索,为了保证搜索结果的准确性和搜索速度,请使用16G内存(memory)以上的设备。以及index存放地点为SSD(固态硬盘)。如果不担心速度,只需要能实现,请忽略第二条,内存达到16G即可。(内存频率和通道数无明显影响。)
此外,EmEditor也有搜索对应文件夹内所有TXT的功能,但是有点烧内存,请自行测试。如果使用正则搜索,则烧CPU。

前接上文《如何高效研究——搜索篇(上)》 且说至本地搜索库的注意事项,接着就是在线库了。 5、爱如生、鼎秀、雕龙等 笔者准备放在一起进行说明,这些是商业库的代表,也是笔者学校没买的库。那么到底要不要花这个钱,在哪花就成了问题。你说贵嘛,也贵,但是相对一…