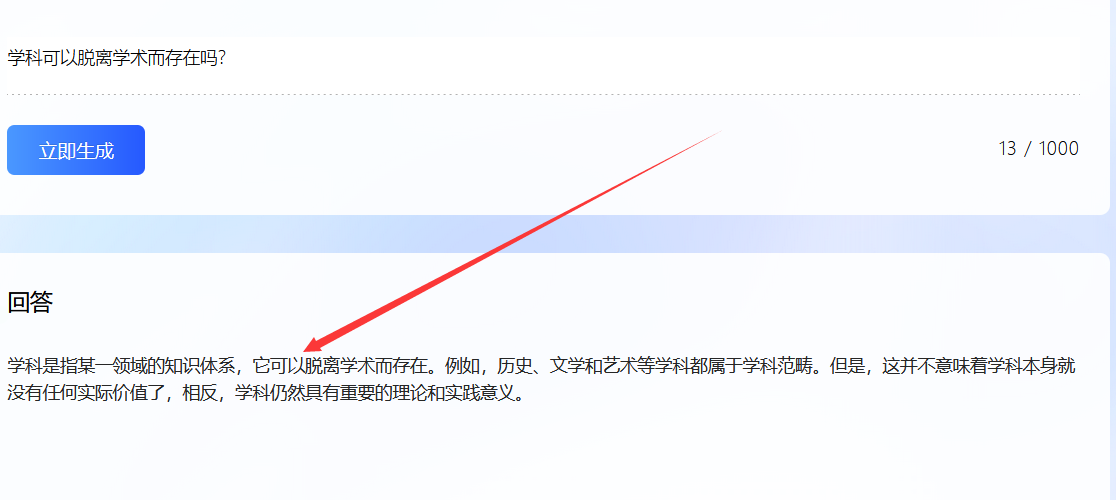
文字是个很神奇的东西,是利用差异进行表意的极致。无论是任何文字的类型,或者放大一点叫做任何传达信息的方式都利用了差异。因为如果相同就只能传递一种甚至什么都不能表达。(在特定情况下除外,早已写入或者被暗示的情况不算,比如说白色。)所以,文字利用了纸面的空白,或者说人类利用了这些差异进行记录。如果一张纸都是白色,那么可能什么都表示不了,但是在上面写上一两笔就不一样了。而用不同的颜色写上一两笔又不一样了。比如说《红字》。但是简简单单的利用空白还不够,需要对文字的差异程度进行处理。相当于是利用差异但是差异到什么样才算另一种意思或者能记录下另一种音符乃至音节。
比如说下面这些,看似都一样,并且人们也倾向于把这些都认为一样的。
文件传偷助手
文件传输助乎
文件转输助手
文仵传输助手
文件传输肋手
但是,很明显,里面混杂了一些差异并不太大的字符,对日常的表意进行误导。这是一种语言的文字系统需要去解决的问题。到底怎么样才算是一个独立的字。
鉴于我自己的水平,我无法完整的论证差异的大小,或者说无法完整度量这个因素。一方面是差异大小与认知相关,如果上面的例子把字单独拿出来放大,可能多数人都能发现其中的问题。但是在大家早已接受文件传输助手这几个字的组合情况下,会默认把类似的字符归一化,相当于下意识的用已有认知去推断这些字符。这在某种程度上是节约思考时间的方式,和打乱顺序依旧可以阅读一样。但是在差异过小却又需要辨析的情况下,只能够主动放慢速度进行辨认。同时,如果差异过多,超过了人类的认知水平,一样无法达到传输或者表达或者记录的效果。类似于某些马赛克,五彩斑斓的它们充满了差异,但是应该没有人用这些形式来记录语言。
另一方面是载体差异,相当于这些字符在哪显示或者说他们利用什么来表达这些差异。说来也奇怪,文字需要表达吗?需要。可以理解为表现形式,在什么上面或者用什么方式看到这些文字的。比如说我这段话的背景颜色用贴近于文字本身的颜色 , 这样一来,就很难辨认出到底里面有啥。(我没有把这个底色改成白色,因为那样的话就没有差异,不符合我们的论证了。)
所以,我们可以说,文字或者说信息的传递,一方面是需要差异,另外一方面是需要完美的表达这些差异。并且在某种程度上需要依靠人类的认知程度和客观载体进行表达。