文章目录[隐藏]
注意
- 一块GPU(主要是快啊)
- 一个下午(主要是有点阴间)
- SSD(等着HDD的4K会让人麻的)
- 一个AI陪着你(稍微智商在线的,比如说gemini2和deepseek)
- ubuntu22.04或者类似的linux系统,看你自己,反正环境配不好才是最大的问题。(其实windows也可以做但是后面有些步骤做不到)
- 一堆图片或者你自己找测试图
- 该连接外网接外网,该换源换源
机器开局
自己去装驱动,cuda用12+吧,cudnn先不急着来。主要是一开始用11.8的那样的话你的其他的开发任务很难搞,所以两个版本的cuda是必须要的。到时候切换软链接就行。

这个是驱动,你可以先装驱动对应的最高cuda版本,我这里就是两个,11.8是专门给paddlex的优化器的。
ls /usr/local/ | grep cuda
我倒是觉得如果只是进行paddle,那样的话用cuda11.8和cudnn8.6先弄好所有的环境变量在往后走。
安装paddle
说真的paddle有坑,第一关就是安装,因为很容易直接到cpu版本去。自己用conda弄个虚拟环境啊。python=3.9的,我没测试3.10
打开文档
2.2 GPU 版的 PaddlePaddle
2.2.1 CUDA11.8 的 PaddlePaddle(依赖 gcc8+, 如果需要使用 TensorRT 可自行安装 TensorRT8.5.3.1)
python3 -m pip install paddlepaddle-gpu==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
三、验证安装
安装完成后您可以使用 python3 进入 python 解释器,输入import paddle ,再输入 paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装。如果出现PaddlePaddle is installed successfully!,说明您已成功安装。
这个时候照着来就行,安装完成的样子大概是
测试
import paddle
print(f"Paddle Version: {paddle.__version__}")
print(f"CUDA Device: {paddle.device.get_device()}")
paddle.utils.run_check()
接着可以先不急着测试,还要继续安装
安装paddlex
打开文档
https://paddlepaddle.github.io/PaddleX/latest/installation/installation.html#1
1.2 插件安装模式¶
若您使用PaddleX的应用场景为二次开发 (例如重新训练模型、微调模型、自定义模型结构、自定义推理代码等),那么推荐您使用功能更加强大的插件安装模式。
安装您需要的PaddleX插件之后,您不仅同样能够对插件支持的模型进行推理与集成,还可以对其进行模型训练等二次开发更高级的操作。
PaddleX支持的插件如下,请您根据开发需求,确定所需的一个或多个插件名称:
👉 插件和产线对应关系(点击展开)
若您需要安装的插件为PaddleXXX,在参考飞桨PaddlePaddle本地安装教程安装飞桨后,您可以直接执行如下指令快速安装PaddleX的对应插件:
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
pip install -e .
paddlex --install PaddleXXX # 例如PaddleOCR
❗ 注:采用这种安装方式后,是可编辑模式安装,当前项目的代码更改,都会直接作用到已经安装的 PaddleX Wheel 包。
如果上述安装方式可以安装成功,则可以跳过接下来的步骤。
若您使用Linux操作系统,请参考2. Linux安装PaddleX详细教程。其他操作系统的安装方式,敬请期待。
说真的, 我不要docker,因为不方便调试和保存,特别是对于这种文件多的要死的情况,反复mount麻烦,而且内部的代码在docker关了可能不保存。
然后记得
paddlex --install PaddleOCR
这样的话就算是差不多了。
测试ocr产线
参考
https://paddlepaddle.github.io/PaddleX/latest/pipeline_usage/tutorials/ocr_pipelines/OCR.html#221
我直接给代码吧,这个是测试代码。
# 最小化测试代码
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="OCR")
output = pipeline.predict("general_ocr_002.png")
for res in output:
res.print()
res.save_to_img("./output/")# 文件夹测试代码
import os
import paddlex as pdx
import time
# 配置文件路径
config_path = "/media/tmzn/DATA5/ocr_paddle/OCR.yaml"
# 图片目录
image_dir = "/media/tmzn/DATA5/music_picture/96197397/"
# 输出结果目录
output_dir = "./ocr_results"
os.makedirs(output_dir, exist_ok=True) # 创建输出目录
# 创建产线
pipeline = pdx.create_pipeline(config_path)
# 计时开始
start_time = time.time()
# 遍历图片目录进行预测
for filename in os.listdir(image_dir):
if filename.lower().endswith((".jpg", ".jpeg", ".png", ".bmp")): # 检查文件扩展名
image_path = os.path.join(image_dir, filename)
output = pipeline.predict(image_path)
# 打印和保存结果
base_name, ext = os.path.splitext(filename) # 分离文件名和扩展名
for res in output:
#res.print() # 仍然打印到终端
# 保存可视化结果图片
res.save_to_img(os.path.join(output_dir, f"{base_name}_result{ext}"))
# 将结果保存为 JSON 文件
res.save_to_json(
save_path=os.path.join(output_dir, f"{base_name}_result.json"),
indent=4, # 使用缩进,使 JSON 文件更易读
ensure_ascii=False # 允许保存非 ASCII 字符(如中文)
)
# 计时结束
end_time = time.time()
total_time = end_time - start_time
print(f"OCR results saved to: {output_dir}")
print(f"Total processing time: {total_time:.2f} seconds")
# 计算平均每张图片的处理时间(如果需要)
num_images = len([f for f in os.listdir(image_dir) if f.lower().endswith((".jpg", ".jpeg", ".png", ".bmp"))])
if num_images > 0:
avg_time_per_image = total_time / num_images
print(f"Average time per image: {avg_time_per_image:.3f} seconds")Global:
pipeline_name: OCR # 产线名称,可以自定义
Pipeline:
text_det_model: PP-OCRv4_mobile_det
text_rec_model: PP-OCRv4_mobile_rec
text_rec_batch_size: 64 # 根据您的GPU显存调整,可适当增大
device: "gpu:0" # 使用的GPU设备,如果使用CPU改为 "cpu"大概这样的配置文件就行,不行就自己去调整一下,上面是生产环境我用的,下面是测试的。
Global:
pipeline_name: OCR
input: https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png
Pipeline:
text_det_model: PP-OCRv4_mobile_det
text_rec_model: PP-OCRv4_mobile_rec
text_rec_batch_size: 1多进程优化
到这一步,实际上多进程的优化已经到了尽头,我还是给出我没加官方优化器的代码吧。
import os
import time
import cv2
import paddlex as pdx
from concurrent.futures import ProcessPoolExecutor
# --- Configuration --- (Keep these outside the function)
config_path = "/media/tmzn/DATA5/ocr_paddle/OCR.yaml"
image_dir = "/media/tmzn/DATA5/music_picture/96197397/"
output_dir = "./ocr_results"
os.makedirs(output_dir, exist_ok=True)
# --- Global variable (within the process) ---
# This will hold the pipeline *for each process*. It's crucial.
global_pipeline = None
def init_worker(config_path_):
"""
Initializes the PaddleX pipeline *once* per process.
This function will be called when each process in the pool starts.
"""
global global_pipeline
print(f"Initializing worker process (PID: {os.getpid()})") # Helpful for debugging
global_pipeline = pdx.create_pipeline(config_path_)
def process_image(image_path):
"""
Processes a single image using the *global* pipeline.
"""
try:
base_name, ext = os.path.splitext(os.path.basename(image_path))
img = cv2.imread(image_path)
if img is None:
raise ValueError(f"Could not open or read image: {image_path}")
# Use the global pipeline!
output = global_pipeline.predict(img)
for res in output:
# res.print() # Uncomment if you want to see per-image results
res.save_to_img(os.path.join(output_dir, f"{base_name}_result{ext}"))
res.save_to_json(
save_path=os.path.join(output_dir, f"{base_name}_result.json"),
indent=4,
ensure_ascii=False
)
except Exception as e:
print(f"Error processing {image_path}: {e}")
# return # No need to return anything here.
if __name__ == '__main__':
image_paths = [
os.path.join(image_dir, filename)
for filename in os.listdir(image_dir)
if filename.lower().endswith((".jpg", ".jpeg", ".png", ".bmp"))
]
start_time = time.time()
with ProcessPoolExecutor(max_workers= 8,
initializer=init_worker,
initargs=(config_path,)) as executor: # Pass config_path
for _ in executor.map(process_image, image_paths):
pass
end_time = time.time()
total_time = end_time - start_time
print(f"OCR results saved to: {output_dir}")
print(f"Total processing time: {total_time:.2f} seconds")
if image_paths:
print(f"Average time per image: {total_time / len(image_paths):.3f} seconds")GPU负载
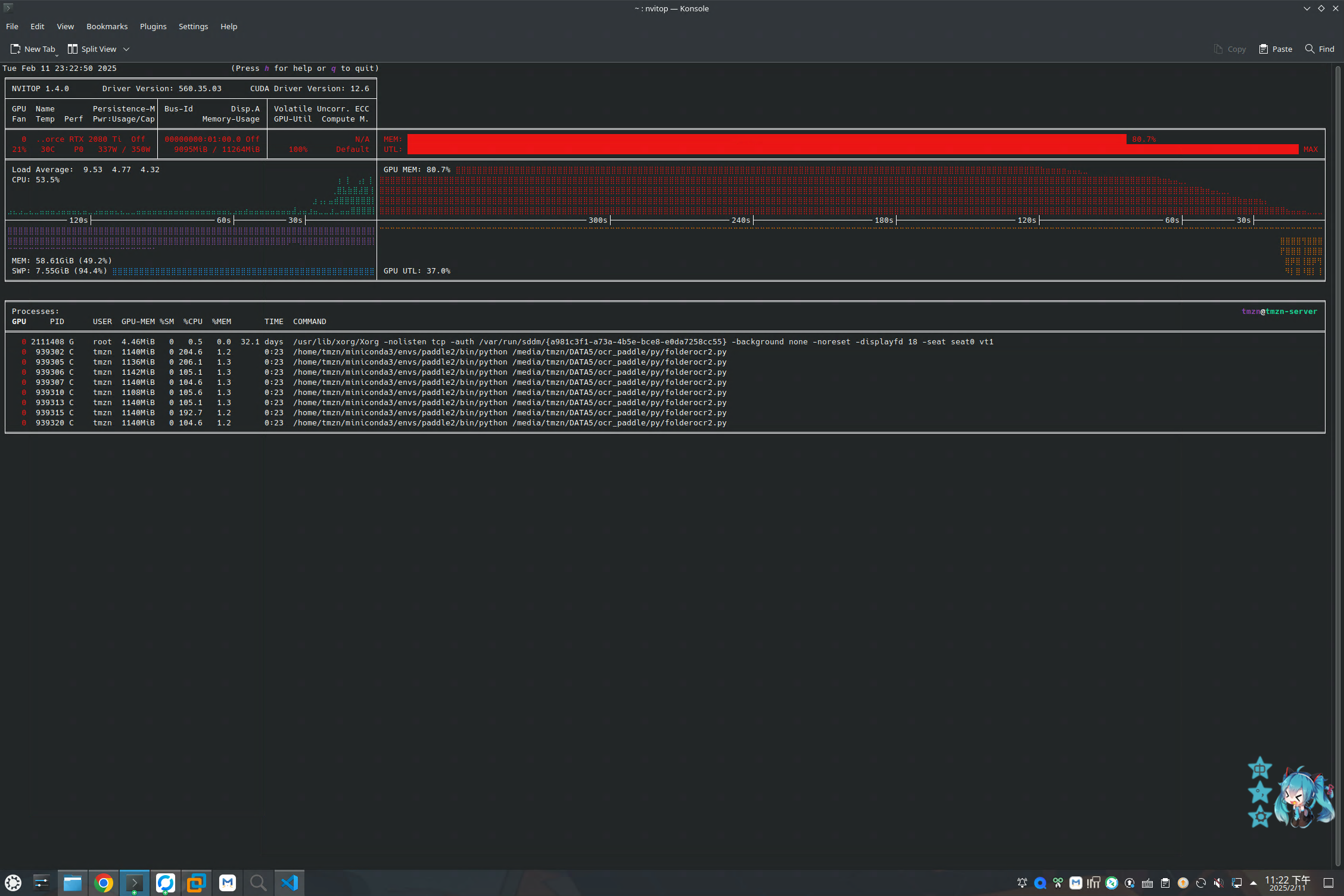
速度
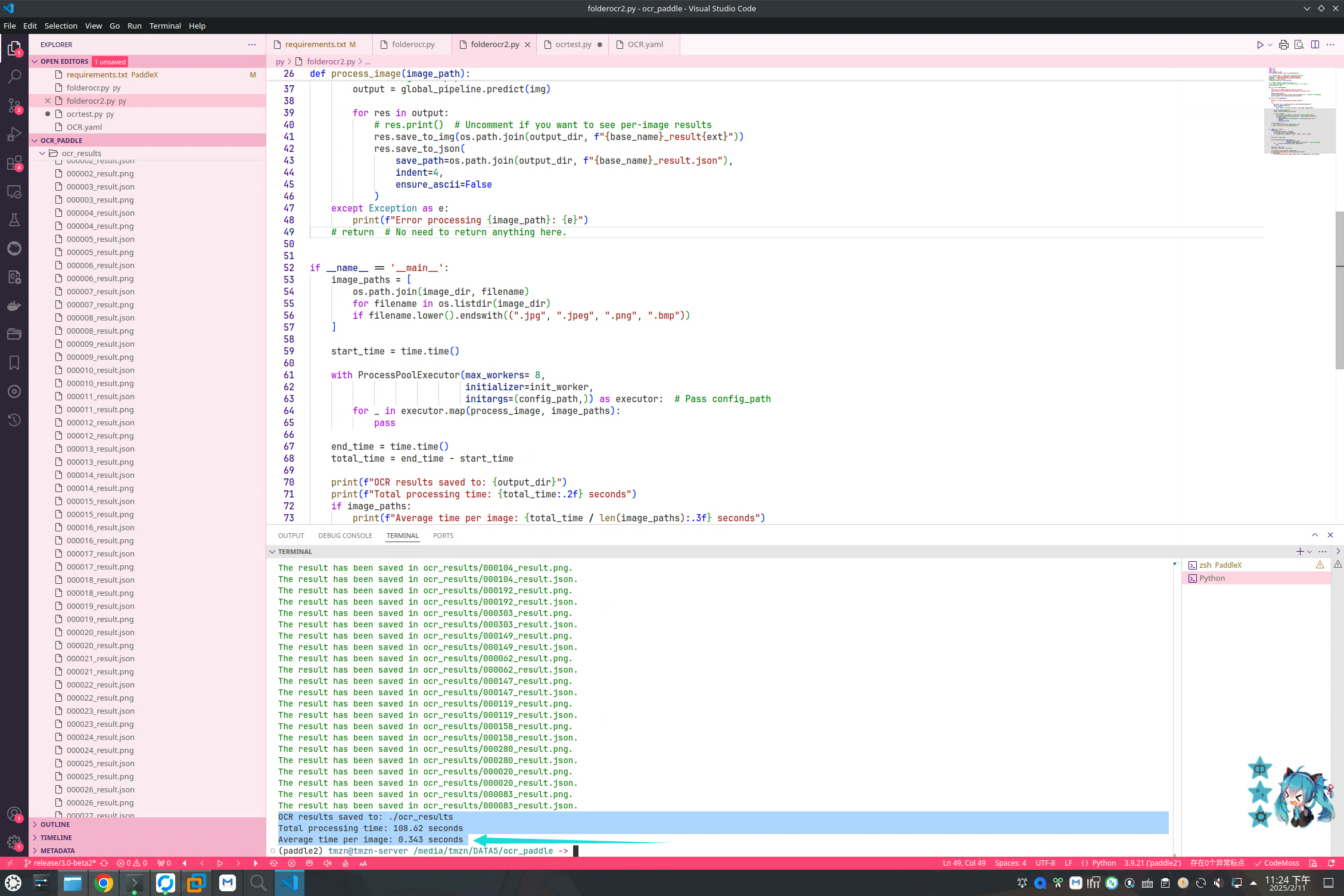
安装官方优化器
参考
https://paddlepaddle.github.io/PaddleX/latest/pipeline_deploy/high_performance_inference.html
我被这个东西坑了,说那么多,实际上就是配环境+调用api
环境按照命令安装,记得自己改一下自己的版本。
也就是说
你只需要安装、申请序列号,联网注册
然后参考
对于 PaddleX Python API,启用高性能推理插件的方法类似。仍以通用图像分类产线为例:

from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="image_classification",
use_hpip=True,#这个部分默认是关着的,你自己打开就行了
hpi_params={"serial_number": "{序列号}"},
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
启用高性能推理插件得到的推理结果与未启用插件时一致。对于部分模型,在首次启用高性能推理插件时,可能需要花费较长时间完成推理引擎的构建。PaddleX 将在推理引擎的第一次构建完成后将相关信息缓存在模型目录,并在后续复用缓存中的内容以提升初始化速度然后我的测试代码如下
import os
import paddlex as pdx
import time
# 配置文件路径
config_path = "/media/tmzn/DATA5/ocr_paddle/config_paddle/OCR.yaml" # 修正:使用正确的配置文件路径
# 图片目录
image_dir = "/media/tmzn/DATA5/music_picture/96197397/"
# 输出结果目录
output_dir = "./ocr_results"
os.makedirs(output_dir, exist_ok=True) # 创建输出目录
# 创建产线,并启用高性能推理插件 (HPI)
# 因为已经激活过,所以不需要再设置 serial_number
pipeline = pdx.create_pipeline(config_path, hpi_params={})
# 计时开始
start_time = time.time()
# 遍历图片目录进行预测
for filename in os.listdir(image_dir):
if filename.lower().endswith((".jpg", ".jpeg", ".png", ".bmp")): # 检查文件扩展名
image_path = os.path.join(image_dir, filename)
output = pipeline.predict(image_path)
# 打印和保存结果
base_name, ext = os.path.splitext(filename) # 分离文件名和扩展名
for res in output:
res.print() # 仍然打印到终端
# 保存可视化结果图片
#pdx.visualize(image_path, res, threshold=0.5, save_dir=output_dir) # 使用pdx.visualize进行可视化
# res.save_to_img(os.path.join(output_dir, f"{base_name}_result{ext}")) # 这一行可以注释掉,因为pdx.visualize已经保存了图片
# 将结果保存为 JSON 文件
res.save_to_json(
save_path=os.path.join(output_dir, f"{base_name}_result.json"),
indent=4, # 使用缩进,使 JSON 文件更易读
ensure_ascii=False, # 允许保存非 ASCII 字符(如中文)
)
# 计时结束
end_time = time.time()
total_time = end_time - start_time
print(f"OCR results saved to: {output_dir}")
print(f"Total processing time: {total_time:.2f} seconds")
# 计算平均每张图片的处理时间(如果需要)
num_images = len(
[
f
for f in os.listdir(image_dir)
if f.lower().endswith((".jpg", ".jpeg", ".png", ".bmp"))
]
)
if num_images > 0:
avg_time_per_image = total_time / num_images
print(f"Average time per image: {avg_time_per_image:.3f} seconds")
# 示例:使用网络图片进行测试(可选)
# output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg")
# print(output)单进程GPU负载
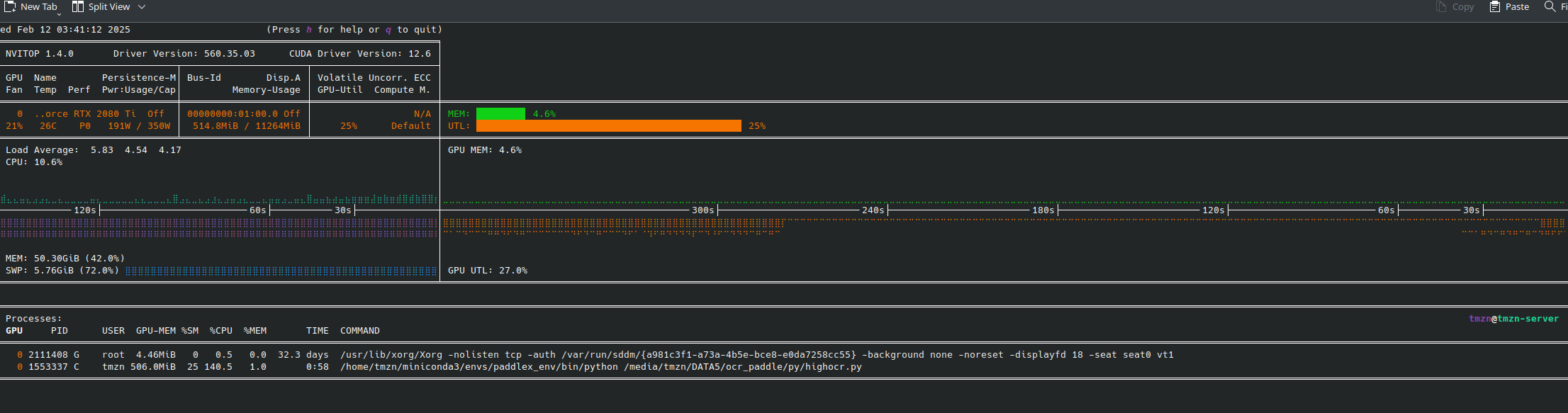
单进程速度

多进程优化
这个玩意我用的是R5100 3.84T的盘,2080TI11G 7302 外加上3200的内存。
我直接放代码吧
import paddlex as pdx
import time
import json
import os
from multiprocessing import Pool, cpu_count, get_context
import paddle
# Disable Paddle's signal handler
#这里是必须要加的,不加会出现报错导致整个程序中断,具体试试就知道了。
paddle.disable_signal_handler()
# Global variable to hold the pipeline *within each worker process*
global_pipeline = None
config_path = "/media/tmzn/DATA5/ocr_paddle/config_paddle/OCR.yaml" # Global config path 这个配置文件用之前的没啥问题
output_dir = "./ocr_results" # Global output directory
def init_worker(config_path, batch_size):
"""
Initializes the worker process. This function runs *once* for each
process in the pool. It creates the PaddleX pipeline and stores it
in a global variable (global *within* the worker process).
"""
global global_pipeline # Declare that we're modifying the global variable
global_pipeline = pdx.create_pipeline(
config_path, hpi_params={"batch_size": batch_size}
)
print(f"Worker process initialized (PID: {os.getpid()})")
def process_image(image_path):
"""
Process a single image using the pre-loaded pipeline.
"""
global global_pipeline # Access the global pipeline
if global_pipeline is None:
raise RuntimeError("Pipeline not initialized in worker process!")
try:
output = global_pipeline.predict(image_path)
base_name = os.path.splitext(os.path.basename(image_path))[0]
for res in output:
# res.print() # Removed for speed
res.save_to_json(
save_path=os.path.join(output_dir, f"{base_name}_result.json"),
indent=4,
ensure_ascii=False,
)
except Exception as e:
print(f"Error processing {image_path}: {e}")
return False # Return False on error
return True
def main():
image_dir = "/media/tmzn/DATA5/music_picture/96197397/"
os.makedirs(output_dir, exist_ok=True) # Ensure output directory
# --- Configuration ---
num_processes = max(1, cpu_count() - 16)#这里自己测试吧,别太多炸显存了,一个506M那么两个1G
batch_size = 64 # Start with 1, increase cautiously if GPU memory allows
# chunk_size = 50 # No longer needed with imap
use_cpu = False
if use_cpu:
config_path_cpu = modify_config_for_cpu(config_path)
config_to_use = config_path_cpu
else:
config_to_use = config_path
def image_path_generator(image_dir):
for filename in os.listdir(image_dir):
if filename.lower().endswith((".jpg", ".jpeg", ".png", ".bmp")):
yield os.path.join(image_dir, filename)
# image_paths = list(image_path_generator(image_dir)) # Not needed with imap
num_images = sum(1 for _ in image_path_generator(image_dir)) # Count for later
print(f"Using {num_processes} processes.")
print(f"Batch size: {batch_size}")
start_time = time.time()
# Use imap/imap_unordered with an initializer. Crucially, use a context manager
# to ensure proper cleanup.
with get_context("spawn").Pool(
processes=num_processes,
initializer=init_worker,
initargs=(config_to_use, batch_size), # Pass config and batch_size to initializer
) as pool:
# Use imap_unordered for speed, as order doesn't matter.
results = pool.imap_unordered(process_image, image_path_generator(image_dir))
# Iterate through results to check for errors (important!) AND force
# the iterator to complete. This is the KEY FIX.
processed_count = 0
for result in results:
processed_count += 1
if result is not True:
print("A process returned an error.")
# Add a progress update (optional, but helpful)
if processed_count % 100 == 0: # Print every 100 images
print(f"Processed {processed_count}/{num_images} images...")
# The loop above ensures all results are consumed. The context manager
# (the `with` statement) handles joining and terminating the worker
# processes *after* the iterator is exhausted.
pool.close() # Explicitly close the pool.
pool.join() # Explicitly wait for processes (though the context manager should do this).
# Explicitly clear the PaddlePaddle cache:
if 'paddle' in locals() or 'paddle' in globals(): # Check paddle
import paddle
if paddle.device.is_compiled_with_cuda():
paddle.device.cuda.empty_cache()
if 'paddlex' in locals() or 'paddlex' in globals():
import paddlex as pdx # Check paddlex
if pdx.env_info()['place'] == 'gpu':
pdx.clear_memory()
end_time = time.time()
total_time = end_time - start_time
print(f"OCR results saved to: {output_dir}")
print(f"Total processing time: {total_time:.2f} seconds")
print(f"Average time per image: {total_time / num_images:.3f} seconds")
def modify_config_for_cpu(config_path):
"""
Modifies the YAML config file to force CPU usage. Creates a *new*
config file with '_cpu' appended to the name.
"""
import yaml # Import the yaml library
base, ext = os.path.splitext(config_path)
new_config_path = f"{base}_cpu{ext}"
with open(config_path, "r") as f:
config = yaml.safe_load(f)
# Modify the relevant settings to force CPU usage
config["Global"]["device"] = "cpu"
# Remove or modify any GPU-specific settings
if "use_gpu" in config["Global"]:
del config["Global"]["use_gpu"]
if "gpu_id" in config["Global"]:
del config["Global"]["gpu_id"]
# You might need to remove or adjust other GPU-related settings
# depending on the specific configuration file. Look for anything
# related to 'gpu', 'cuda', etc.
with open(new_config_path, "w") as f:
yaml.dump(config, f)
return new_config_path
if __name__ == "__main__":
main()GPU负载情况
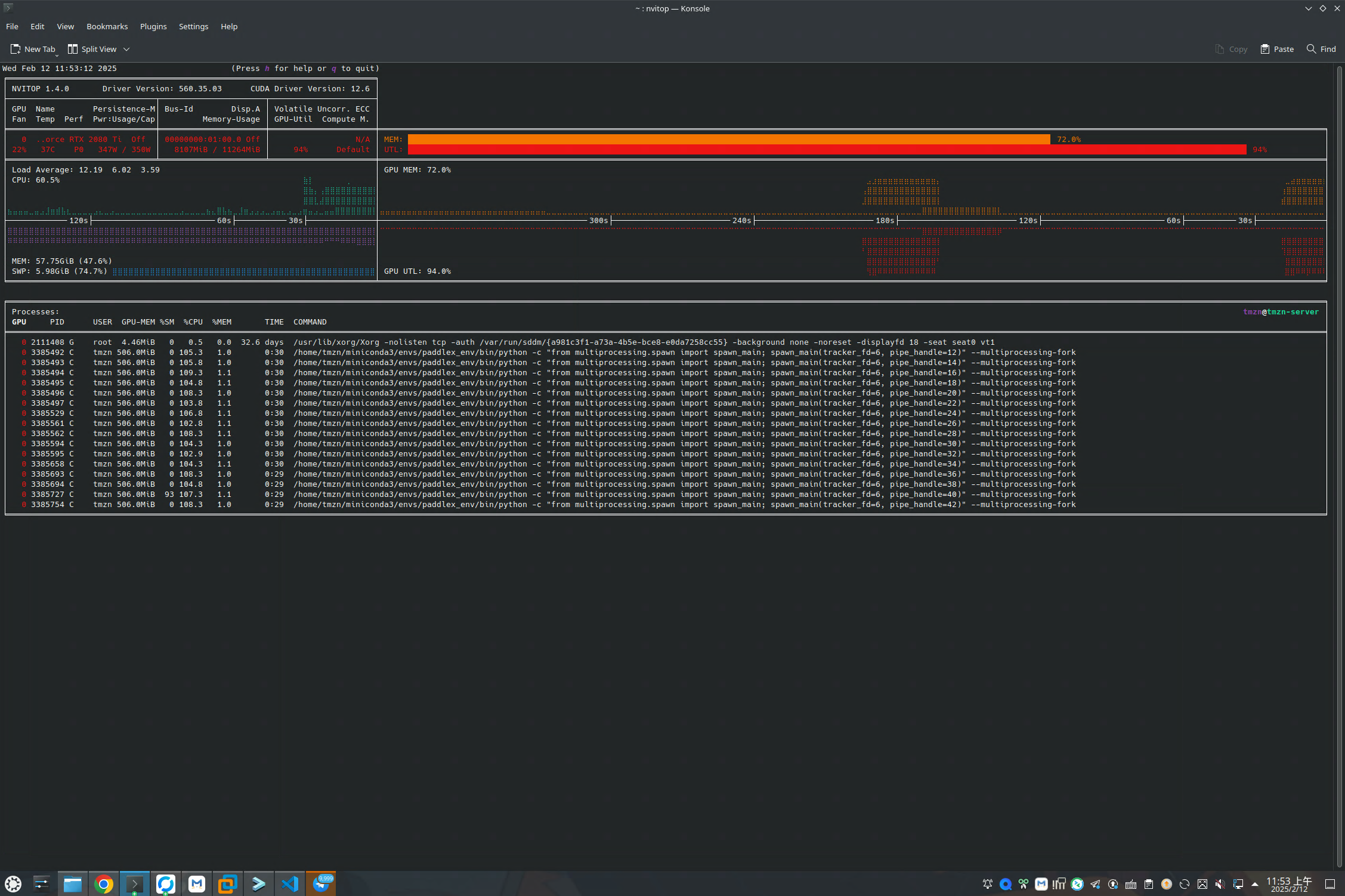
大概啊
反正每次都可能不大一样
速度
目前最快

这是后面又测试了
W0212 12:23:42.970182 3498259 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 12.6, Runtime API Version: 11.8
W0212 12:23:42.972080 3498259 gpu_resources.cc:164] device: 0, cuDNN Version: 8.6.
OCR results saved to: ./ocr_results
Total processing time: 36.16 seconds
Average time per image: 0.114 seconds
Successfully processed images: 317/317paddle特性
你看看这种临时文件夹不清空的,到时候自己记得写一行代码清理一下,我上面没写。
路径看图。
